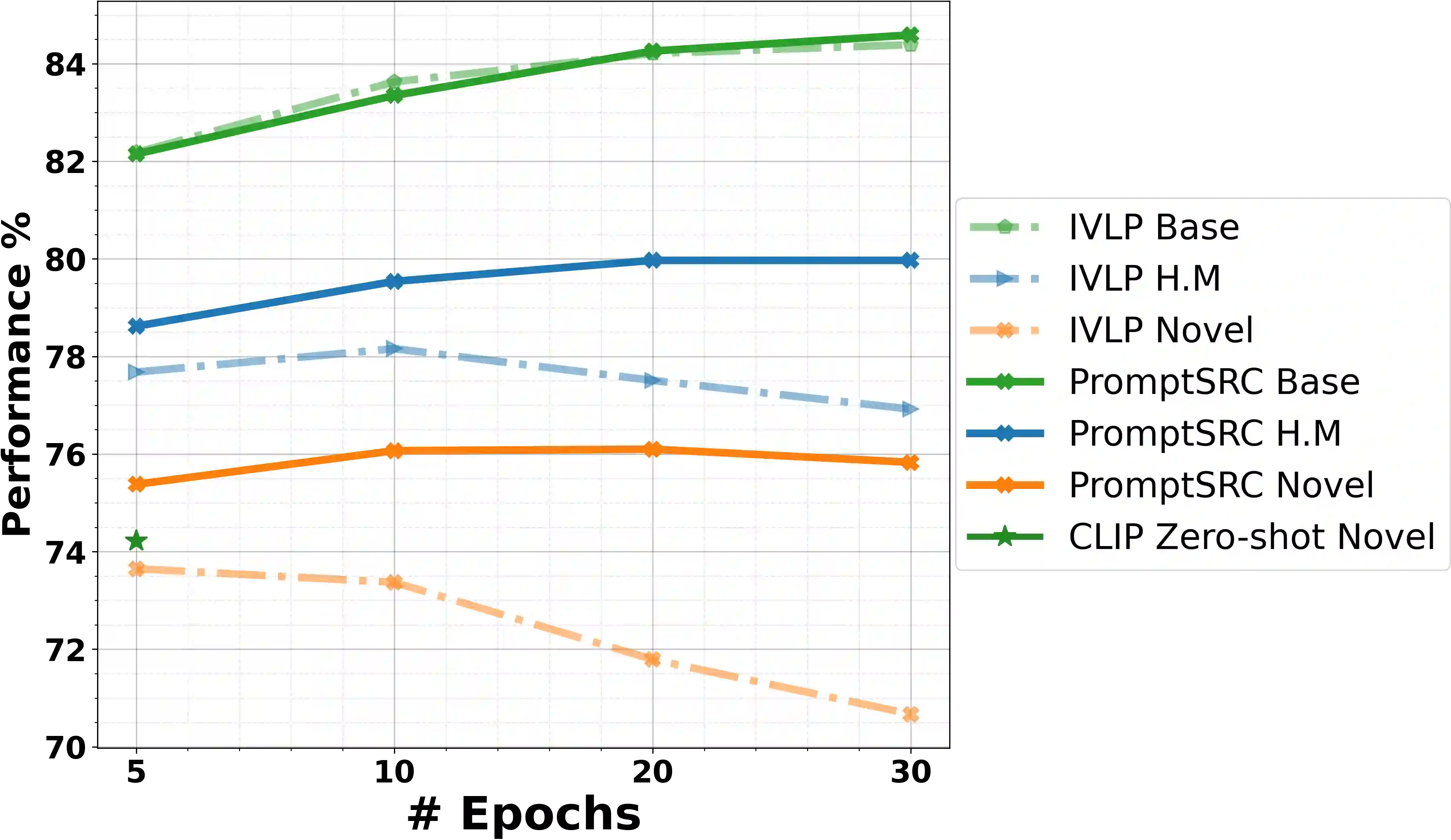
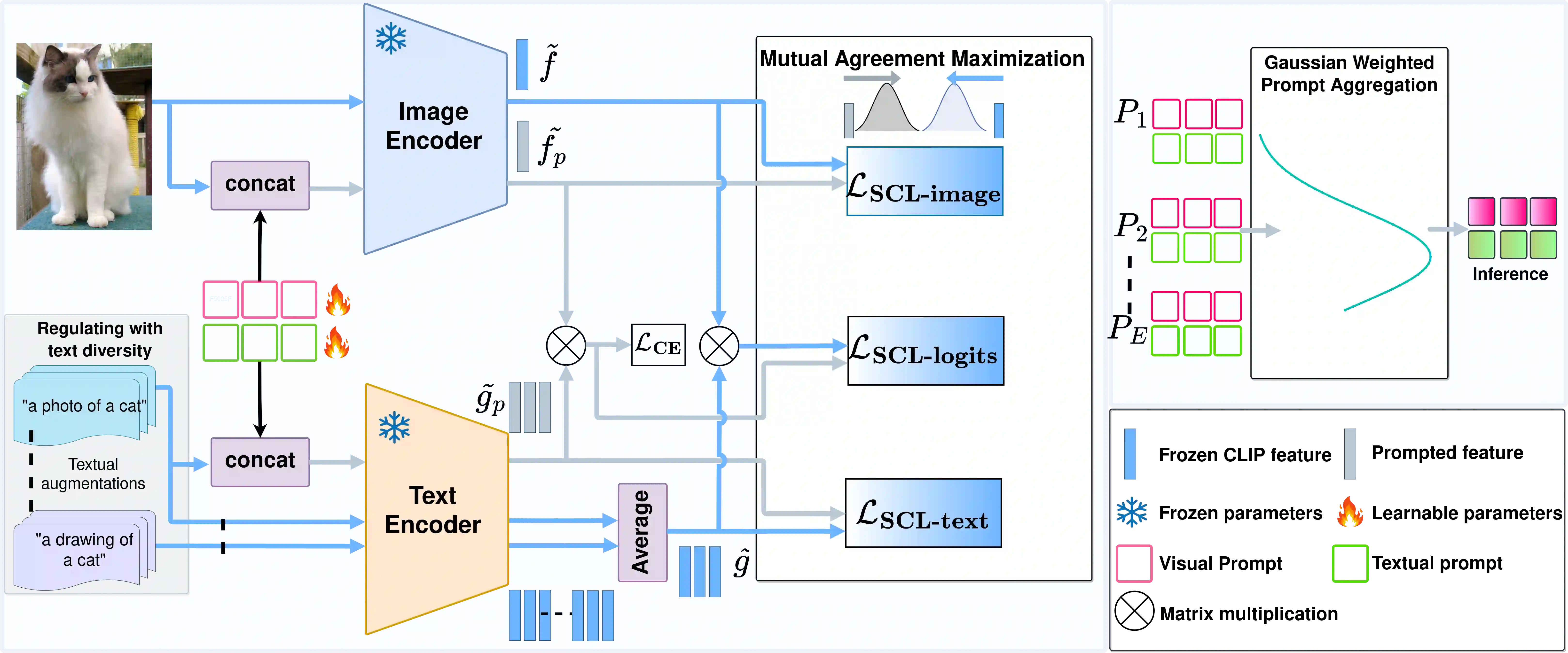
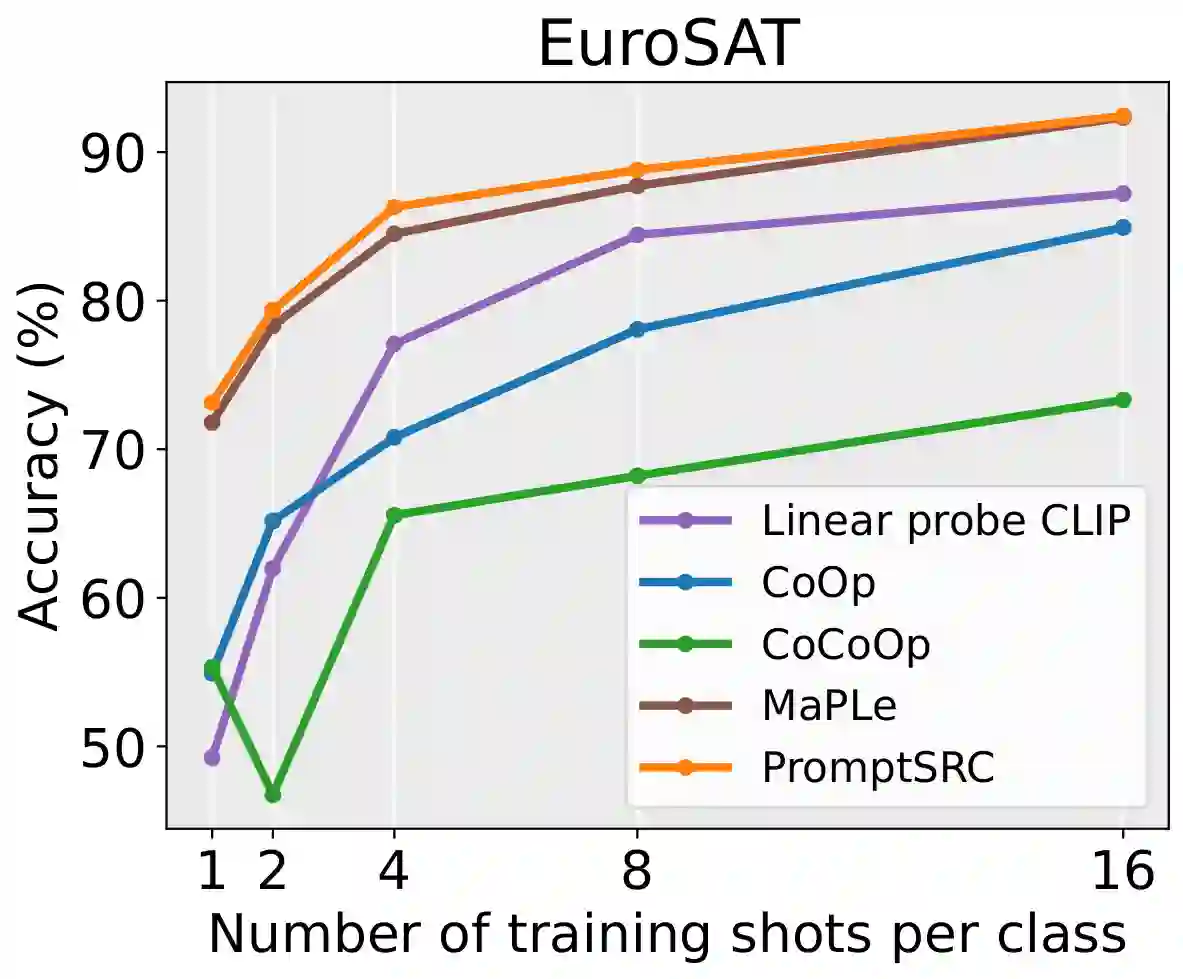
Prompt learning has emerged as an efficient alternative for fine-tuning foundational models, such as CLIP, for various downstream tasks. Conventionally trained using the task-specific objective, i.e., cross-entropy loss, prompts tend to overfit downstream data distributions and find it challenging to capture task-agnostic general features from the frozen CLIP. This leads to the loss of the model's original generalization capability. To address this issue, our work introduces a self-regularization framework for prompting called PromptSRC (Prompting with Self-regulating Constraints). PromptSRC guides the prompts to optimize for both task-specific and task-agnostic general representations using a three-pronged approach by: (a) regulating prompted representations via mutual agreement maximization with the frozen model, (b) regulating with self-ensemble of prompts over the training trajectory to encode their complementary strengths, and (c) regulating with textual diversity to mitigate sample diversity imbalance with the visual branch. To the best of our knowledge, this is the first regularization framework for prompt learning that avoids overfitting by jointly attending to pre-trained model features, the training trajectory during prompting, and the textual diversity. PromptSRC explicitly steers the prompts to learn a representation space that maximizes performance on downstream tasks without compromising CLIP generalization. We perform extensive experiments on 4 benchmarks where PromptSRC overall performs favorably well compared to the existing methods. Our code and pre-trained models are publicly available at: https://github.com/muzairkhattak/PromptSRC.
翻译:提示学习已成为微调CLIP等基础模型以适配各类下游任务的高效替代方案。传统上采用任务特定目标(即交叉熵损失)训练的提示易过度拟合下游数据分布,且难以从冻结的CLIP中捕获任务无关的通用特征,导致模型原始泛化能力丧失。为解决此问题,本文提出名为PromptSRC(带自约束的提示学习)的自正则化框架。该框架通过三管齐下的策略引导提示优化任务特定与任务无关的通用表示:(a)通过最大化与冻结模型的互一致性调节提示表示;(b)利用训练轨迹中提示的自集成编码其互补优势;(c)引入文本多样性以缓解视觉分支的样本多样性失衡。据我们所知,这是首个通过联合关注预训练模型特征、提示训练轨迹及文本多样性来避免过拟合的提示学习正则化框架。PromptSRC明确引导提示学习一个在不削弱CLIP泛化能力的前提下最大化下游任务性能的表示空间。我们在四个基准数据集上开展广泛实验,结果表明PromptSRC整体性能优于现有方法。我们的代码和预训练模型已开源至:https://github.com/muzairkhattak/PromptSRC。