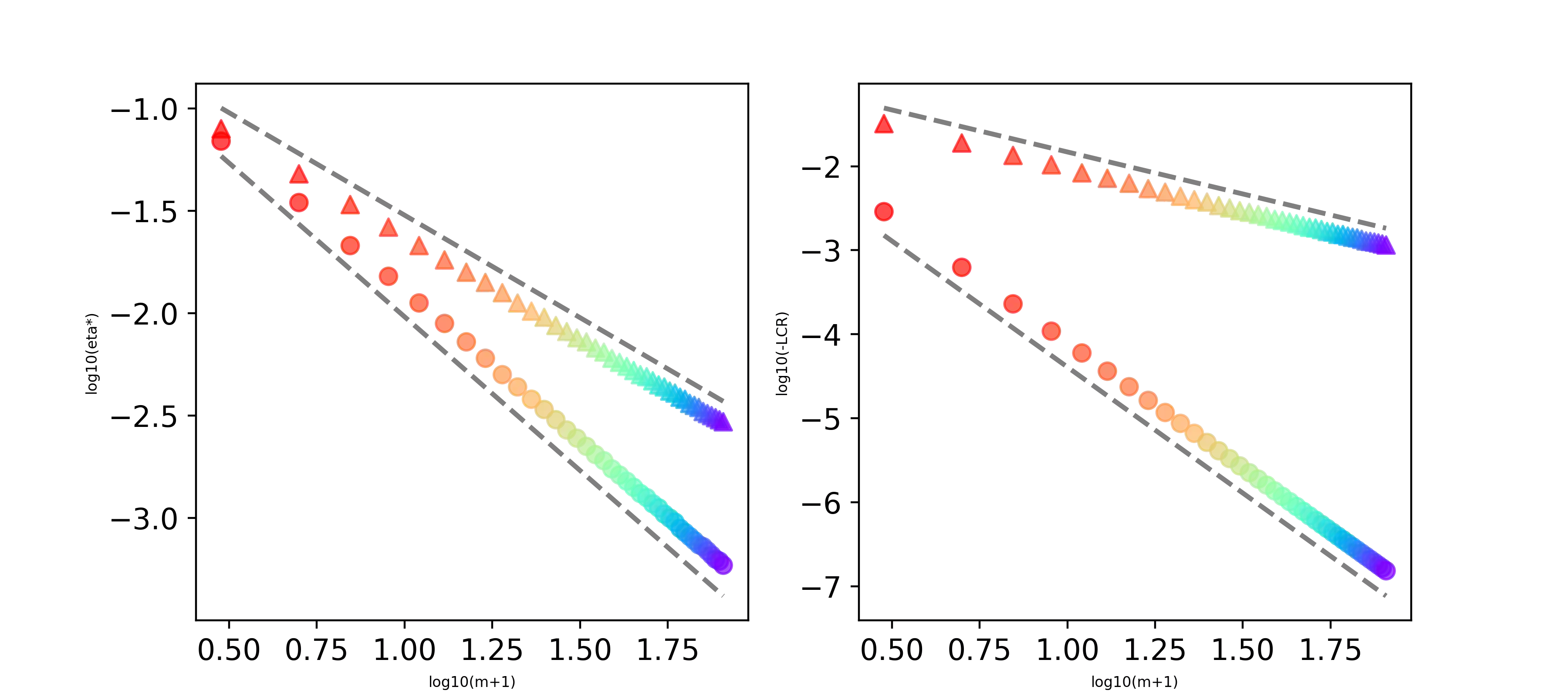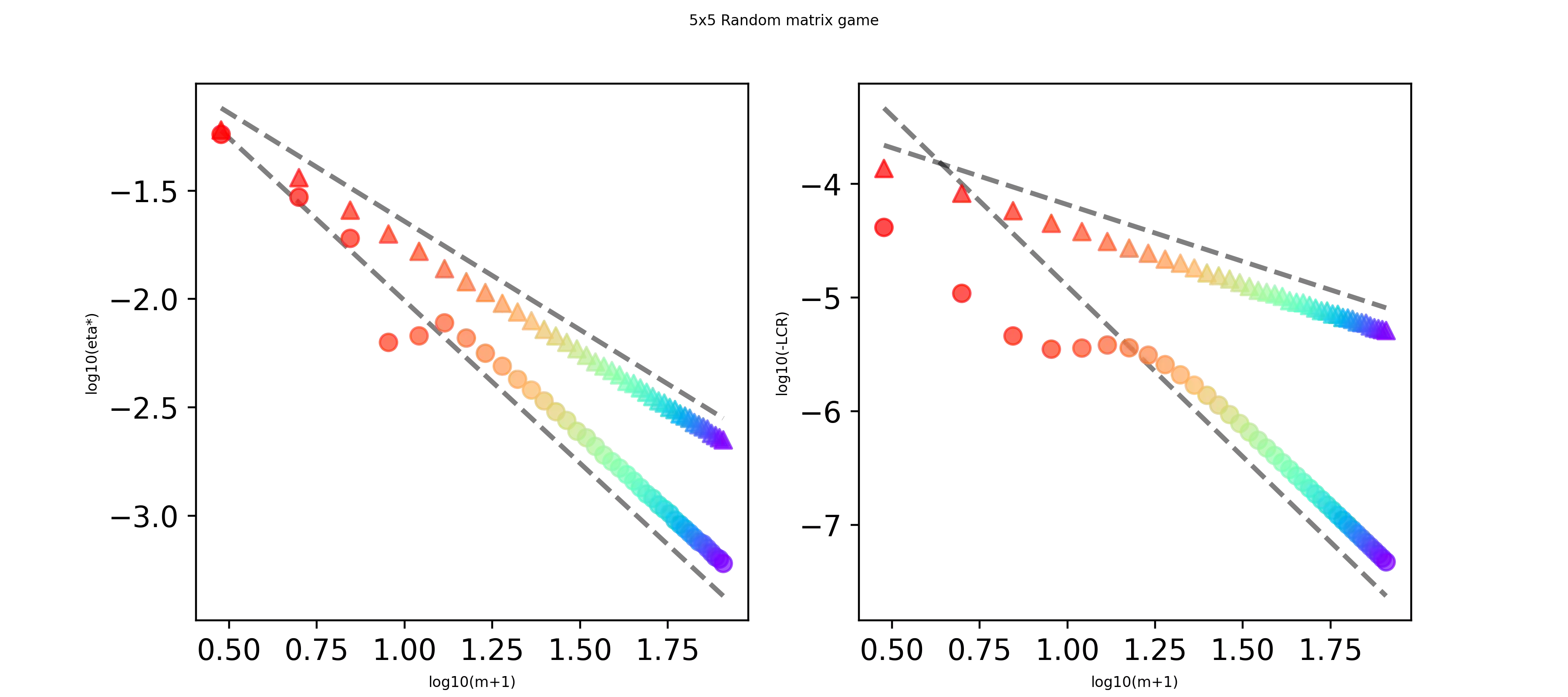Feedback delays are inevitable in real-world multi-agent learning. They are known to severely degrade performance, and the convergence rate under delayed feedback is still unclear, even for bilinear games. This paper derives the rate of linear convergence of Weighted Optimistic Gradient Descent-Ascent (WOGDA), which predicts future rewards with extra optimism, in unconstrained bilinear games. To analyze the algorithm, we interpret it as an approximation of the Extra Proximal Point (EPP), which is updated based on farther future rewards than the classical Proximal Point (PP). Our theorems show that standard optimism (predicting the next-step reward) achieves linear convergence to the equilibrium at a rate $\exp(-Θ(t/m^{5}))$ after $t$ iterations for delay $m$. Moreover, employing extra optimism (predicting farther future reward) tolerates a larger step size and significantly accelerates the rate to $\exp(-Θ(t/(m^{2}\log m)))$. Our experiments also show accelerated convergence driven by the extra optimism and are qualitatively consistent with our theorems. In summary, this paper validates that extra optimism is a promising countermeasure against performance degradation caused by feedback delays.
翻译:在实际多智能体学习中,反馈延迟不可避免。已知延迟会严重降低性能,且即使在双线性博弈中,延迟反馈下的收敛速率仍不明确。本文推导了加权乐观梯度下降上升法在无约束双线性博弈中的线性收敛速率,该方法通过额外乐观度预测未来奖励。为分析该算法,我们将其解释为额外近端点法的近似,其更新基于比经典近端点法更远的未来奖励。我们的定理表明,标准乐观法(预测下一步奖励)在延迟为 $m$ 时,经过 $t$ 次迭代后以 $\exp(-Θ(t/m^{5}))$ 的速率线性收敛至均衡。此外,采用额外乐观法(预测更远未来奖励)可容忍更大的步长,并将速率显著提升至 $\exp(-Θ(t/(m^{2}\log m)))$。我们的实验也显示出由额外乐观度驱动的加速收敛现象,且定性符合理论结果。综上所述,本文验证了额外乐观度是应对反馈延迟导致性能下降的有效策略。