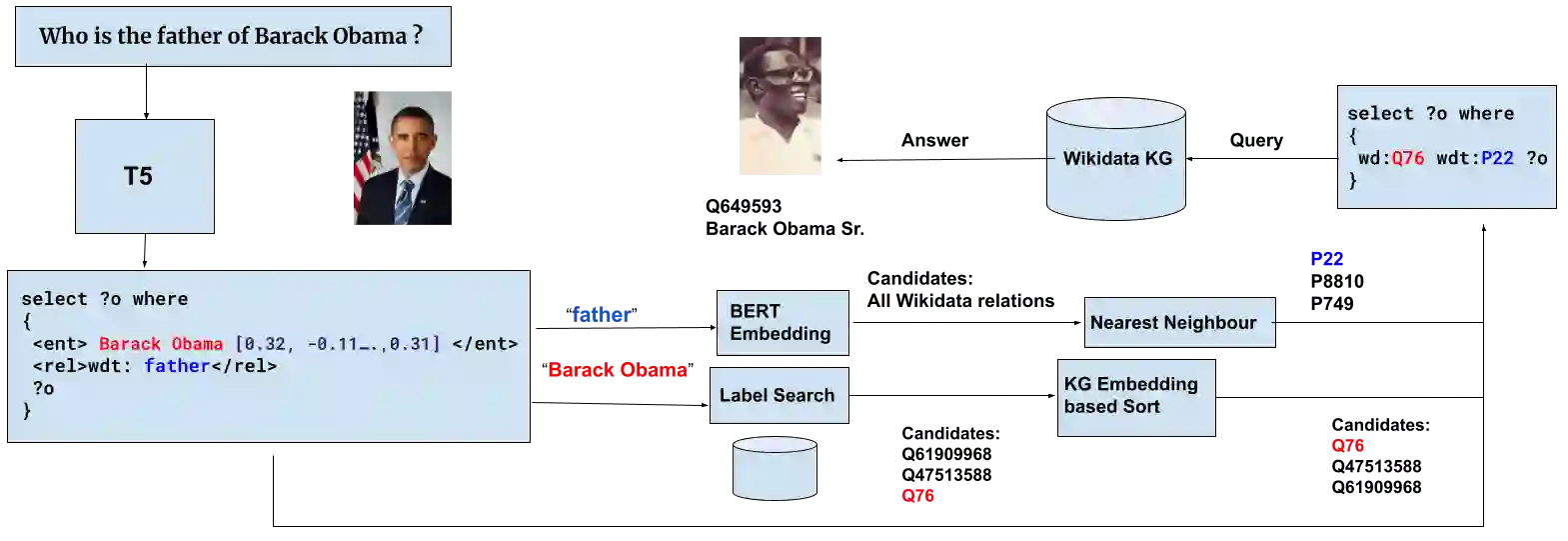
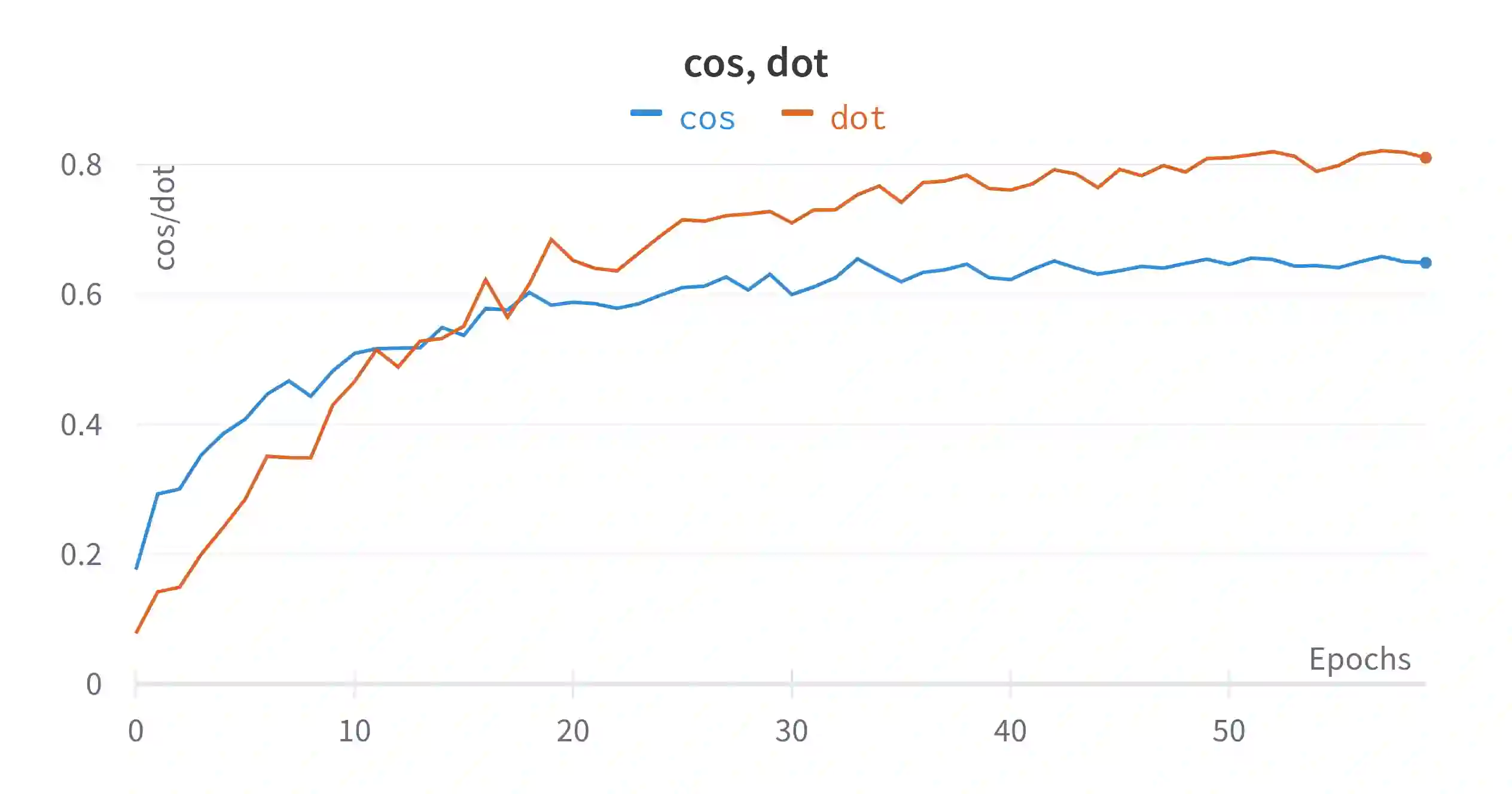
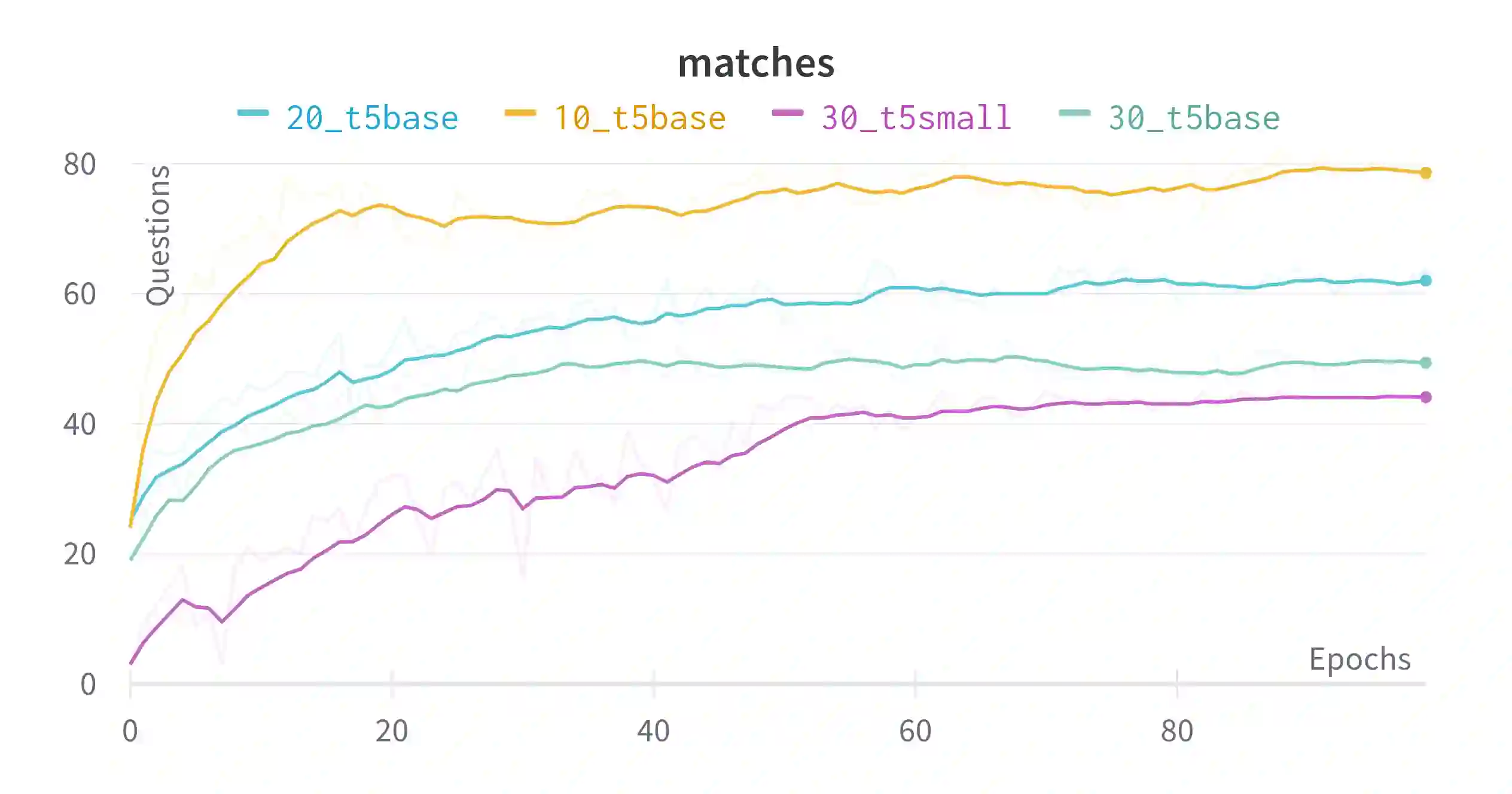
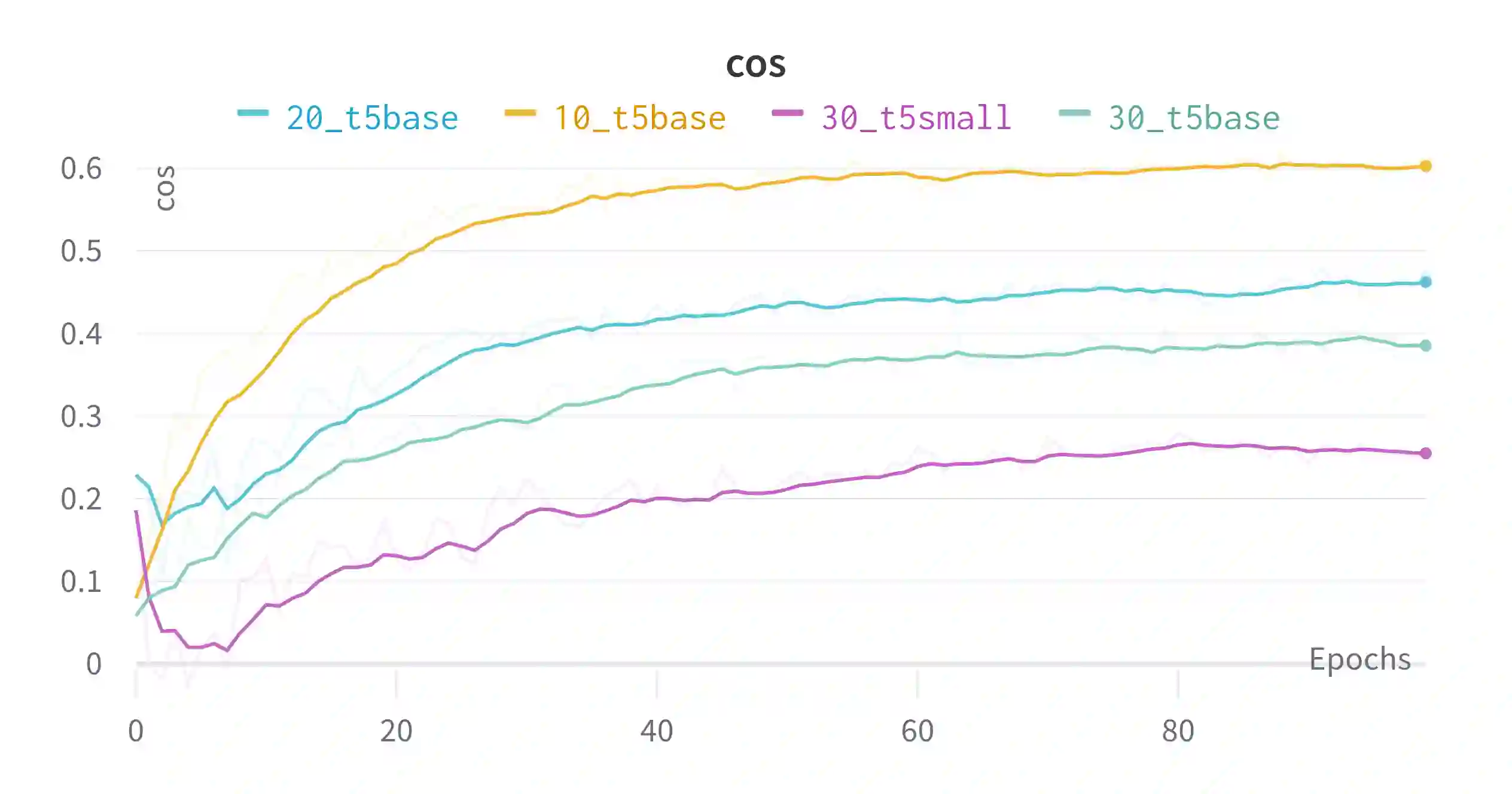
In this work, we present an end-to-end Knowledge Graph Question Answering (KGQA) system named GETT-QA. GETT-QA uses T5, a popular text-to-text pre-trained language model. The model takes a question in natural language as input and produces a simpler form of the intended SPARQL query. In the simpler form, the model does not directly produce entity and relation IDs. Instead, it produces corresponding entity and relation labels. The labels are grounded to KG entity and relation IDs in a subsequent step. To further improve the results, we instruct the model to produce a truncated version of the KG embedding for each entity. The truncated KG embedding enables a finer search for disambiguation purposes. We find that T5 is able to learn the truncated KG embeddings without any change of loss function, improving KGQA performance. As a result, we report strong results for LC-QuAD 2.0 and SimpleQuestions-Wikidata datasets on end-to-end KGQA over Wikidata.
翻译:摘要:本文提出了一种名为GETT-QA的端到端知识图谱问答系统。GETT-QA采用T5——一种流行的文本到文本预训练语言模型。该模型以自然语言问题作为输入,并生成目标SPARQL查询的简化形式。在简化形式中,模型不直接生成实体与关系的标识符,而是输出对应的实体与关系标签。在后续步骤中,这些标签被映射到知识图谱中的实体与关系标识符。为进一步提升结果,我们引导模型为每个实体生成截断版本的知识图谱嵌入。截断后的知识图谱嵌入能够实现更精细的消歧搜索。研究发现,T5无需修改损失函数即可学习截断后的知识图谱嵌入,从而提升知识图谱问答性能。基于此,我们在针对维基数据的端到端知识图谱问答任务上,针对LC-QuAD 2.0和SimpleQuestions-Wikidata数据集取得了优异的结果。