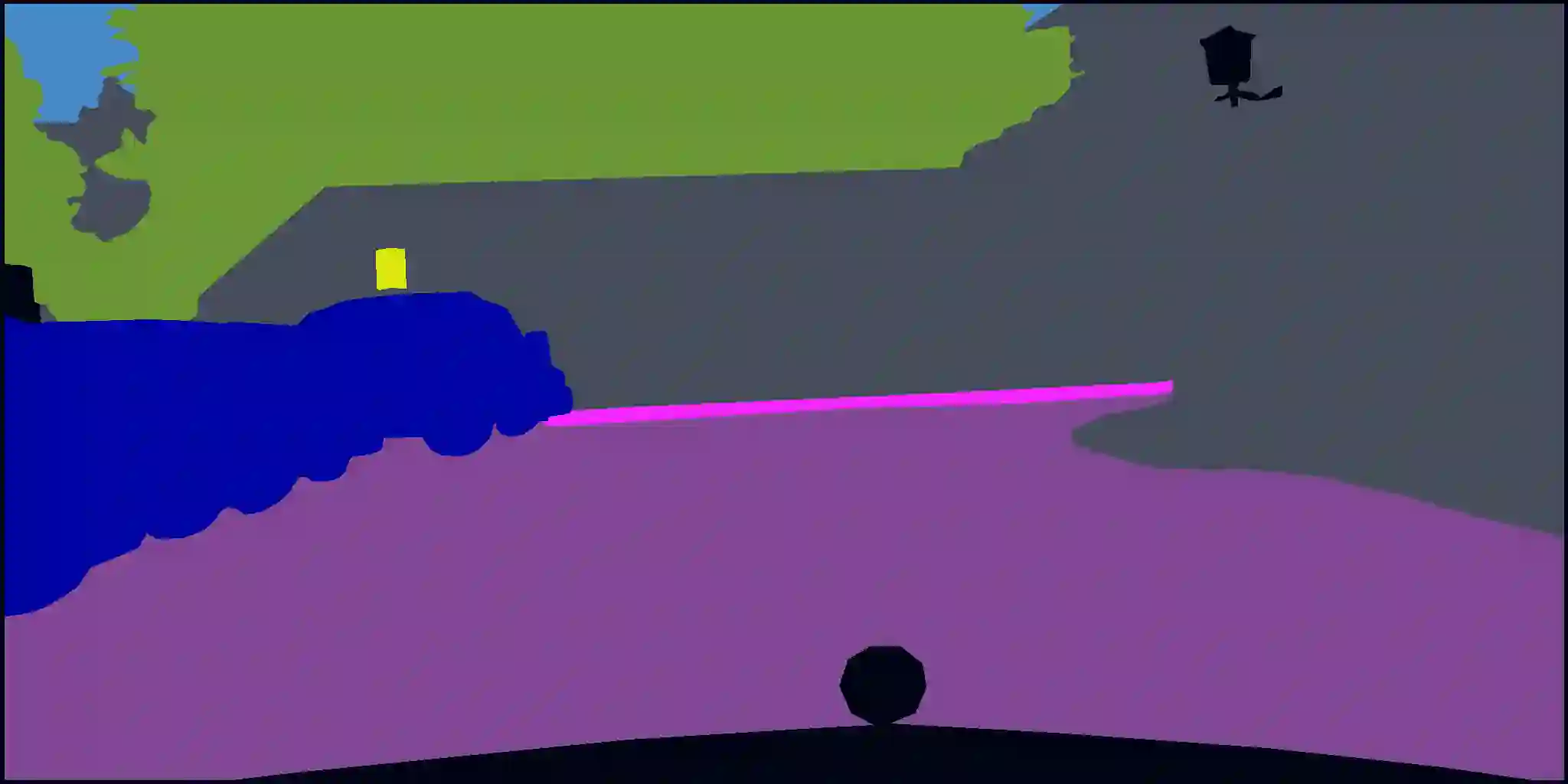
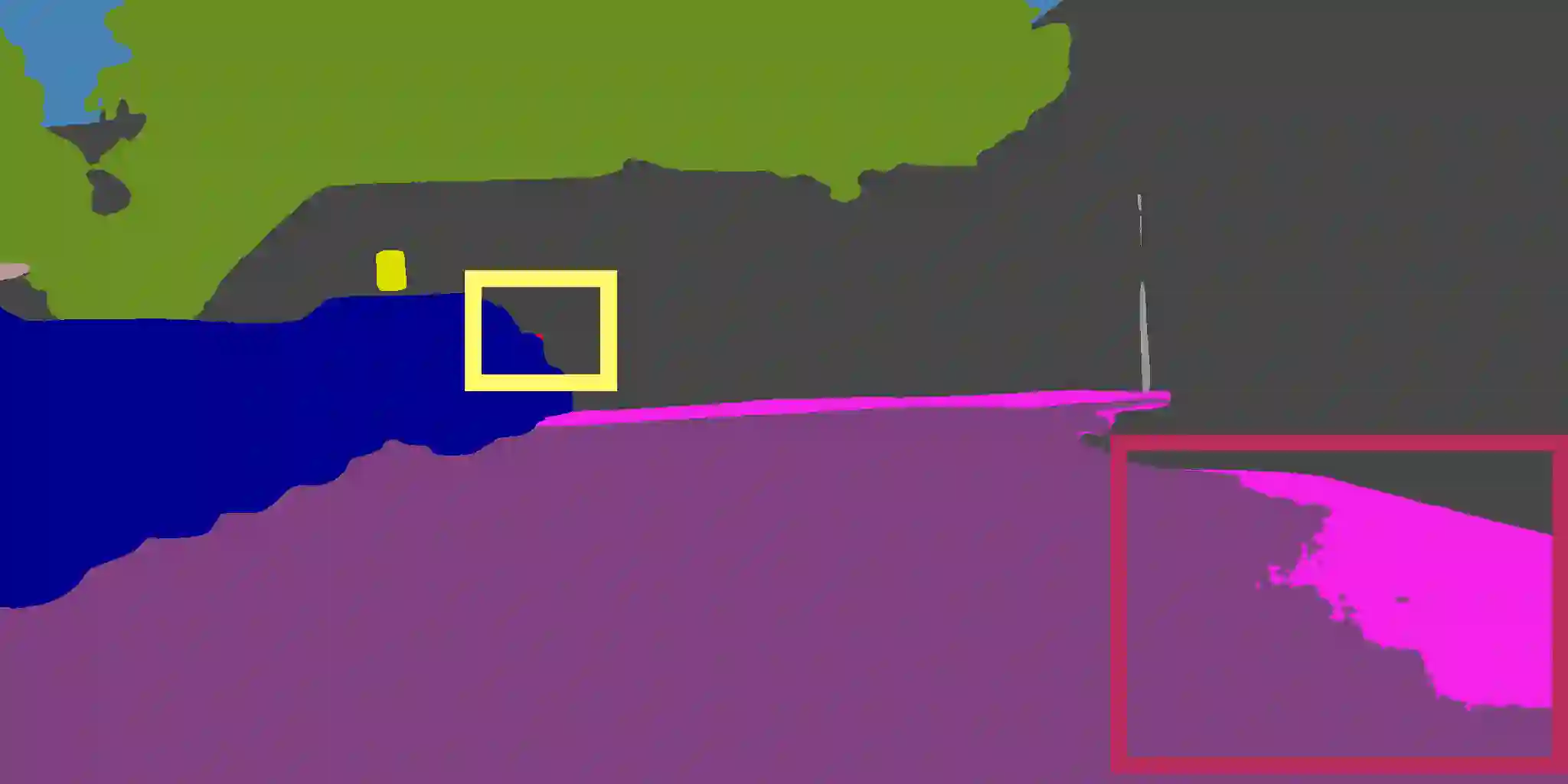
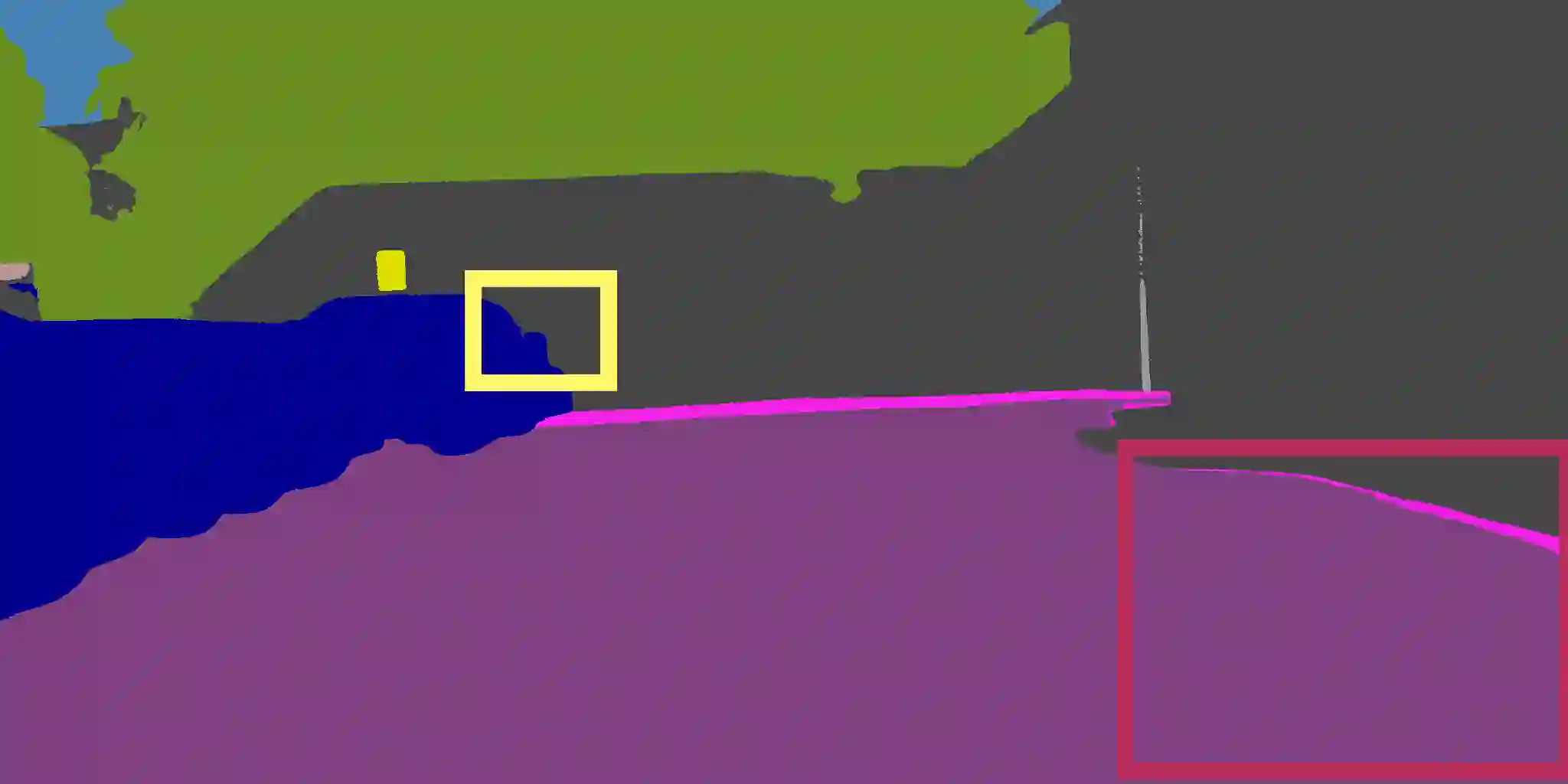
Semantic segmentation is a fundamental task in visual scene understanding. We focus on the supervised setting, where ground-truth semantic annotations are available. Based on knowledge about the high regularity of real-world scenes, we propose a method for improving class predictions by learning to selectively exploit information from neighboring pixels. In particular, our method is based on the prior that for each pixel, there is a seed pixel in its close neighborhood sharing the same prediction with the former. Motivated by this prior, we design a novel two-head network, named Offset Vector Network (OVeNet), which generates both standard semantic predictions and a dense 2D offset vector field indicating the offset from each pixel to the respective seed pixel, which is used to compute an alternative, seed-based semantic prediction. The two predictions are adaptively fused at each pixel using a learnt dense confidence map for the predicted offset vector field. We supervise offset vectors indirectly via optimizing the seed-based prediction and via a novel loss on the confidence map. Compared to the baseline state-of-the-art architectures HRNet and HRNet+OCR on which OVeNet is built, the latter achieves significant performance gains on three prominent benchmarks for semantic segmentation, namely Cityscapes, ACDC and ADE20K. Code is available at https://github.com/stamatisalex/OVeNet
翻译:语义分割是视觉场景理解中的基础任务。我们聚焦于有监督设定,即真实语义标注可用。基于现实世界场景高度规律性的认识,我们提出了一种通过有选择地利用邻域像素信息改进类别预测的方法。具体而言,该方法基于以下先验:对于每个像素,其近邻区域内存在一个共享相同预测的种子像素。受该先验启发,我们设计了一种新颖的双头网络,命名为偏移向量网络(OVeNet),该网络同时生成标准语义预测和一个密集的二维偏移向量场。该偏移向量场指示每个像素到对应种子像素的偏移量,用于计算基于种子像素的替代语义预测。通过预测偏移向量场的学习密集置信度图,两种预测在每个像素处自适应融合。我们通过优化基于种子像素的预测以及针对置信度图的新颖损失函数,间接监督偏移向量。与OVeNet所基于的基线先进架构HRNet和HRNet+OCR相比,OVeNet在三个著名的语义分割基准(Cityscapes、ACDC和ADE20K)上取得了显著的性能提升。代码已开源:https://github.com/stamatisalex/OVeNet