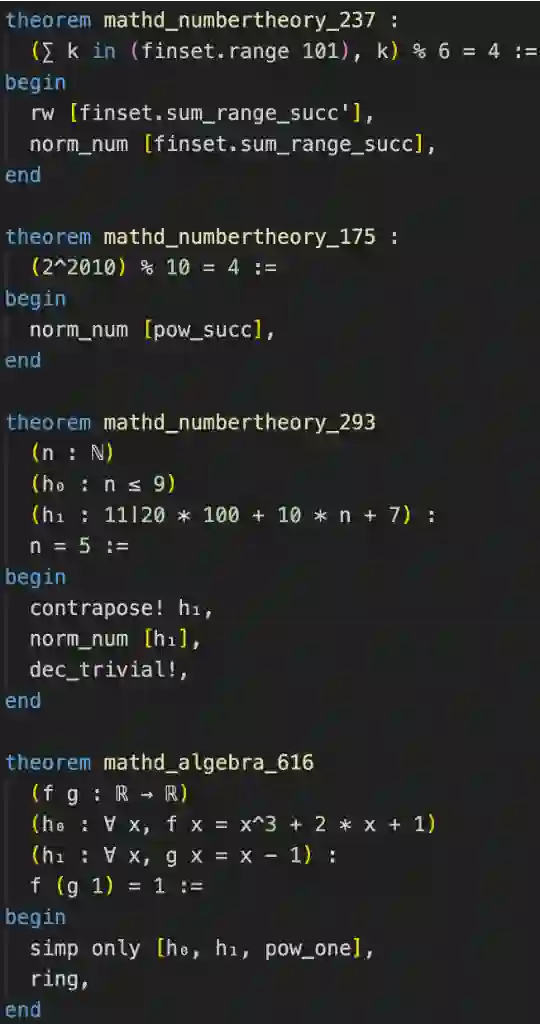
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection: a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): an LLM-based prover augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 98,734 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training and evaluation, and experimental results demonstrate the effectiveness of ReProver over non-retrieval baselines and GPT-4. We thus provide the first set of open-source LLM-based theorem provers without any proprietary datasets and release it under a permissive MIT license to facilitate further research.
翻译:大型语言模型在利用Lean等证明助手进行形式化定理证明方面展现出潜力。然而,现有方法存在代码非公开、数据不透明以及计算资源需求庞大等问题,导致难以复现或在此基础上开展研究,这为基于机器学习的定理证明方法研究设置了重大障碍。本文通过引入LeanDojo——包含工具包、数据、模型和基准测试的开源Lean平台——消除了这些障碍。LeanDojo从Lean中提取数据,并支持以编程方式与证明环境交互。其中包含对证明中前提条件的细粒度标注,为前提选择(定理证明的关键瓶颈)提供了宝贵数据。基于此数据,我们开发了ReProver(检索增强证明器):一种通过检索从庞大数学库中选择前提的LLM证明器。该方法成本低廉,仅需一个GPU周的算力进行训练。我们的检索器利用LeanDojo的程序分析能力识别可访问前提和困难负样本,显著提升了检索效率。此外,我们构建了包含Lean数学库中98,734个定理及证明的新基准数据集,其独特的数据划分要求证明器能够从未在训练中见过的全新前提所对应的定理进行泛化。我们使用该基准进行训练和评估,实验结果表明ReProver相较于非检索基线方法和GPT-4具有显著优势。因此,我们提供了首个无需专有数据集的完全开源LLM定理证明器,并按照宽松的MIT许可证发布,以促进后续研究。