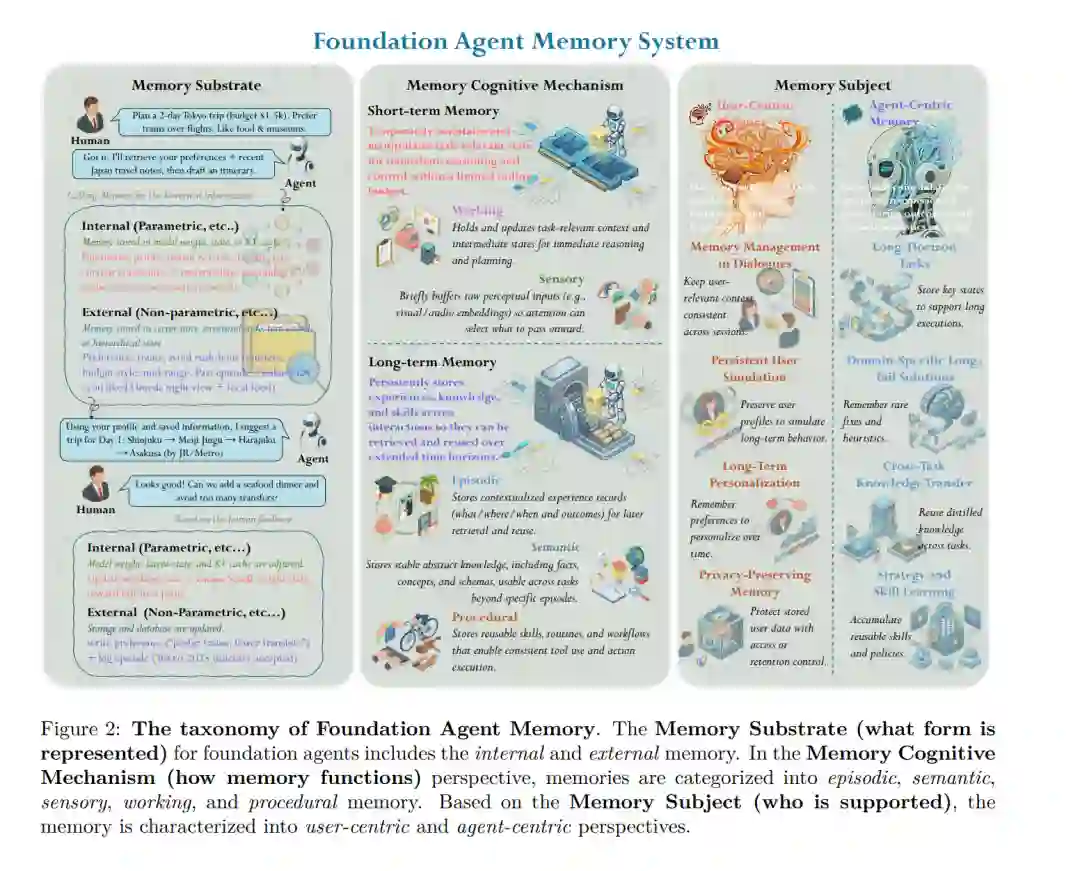
人工智能研究正经历一场范式转移:从优先考虑模型创新与基准测试(Benchmarks)分数,转向强调问题定义与严谨的现实世界评估。随着该领域进入“下半场”,核心挑战转变为在长程(Long-horizon)、动态且依赖用户的环境中实现真正的效用。在这些环境中,智能体(Agents)面临着“上下文爆炸”的挑战,必须在长期的交互过程中持续积累、管理并选择性地重用海量信息。因此,记忆机制——今年已有数百篇相关论文发表——成为填补这一效用鸿沟的关键解决方案。 在本综述中,我们从三个维度提供了基础代理记忆的统一视角:记忆基质(内部与外部)、认知机制(情节性、语义性、感觉性、工作性和程序性记忆)以及记忆主体(以智能体为中心与以用户为中心)。随后,我们分析了在不同代理拓扑结构下,记忆是如何实例化与运行的,并重点阐述了针对记忆操作的学习策略。最后,我们梳理了评估记忆效用的基准测试与指标,并总结了当前面临的各种公开挑战与未来发展方向。
1 引言 (Introduction)
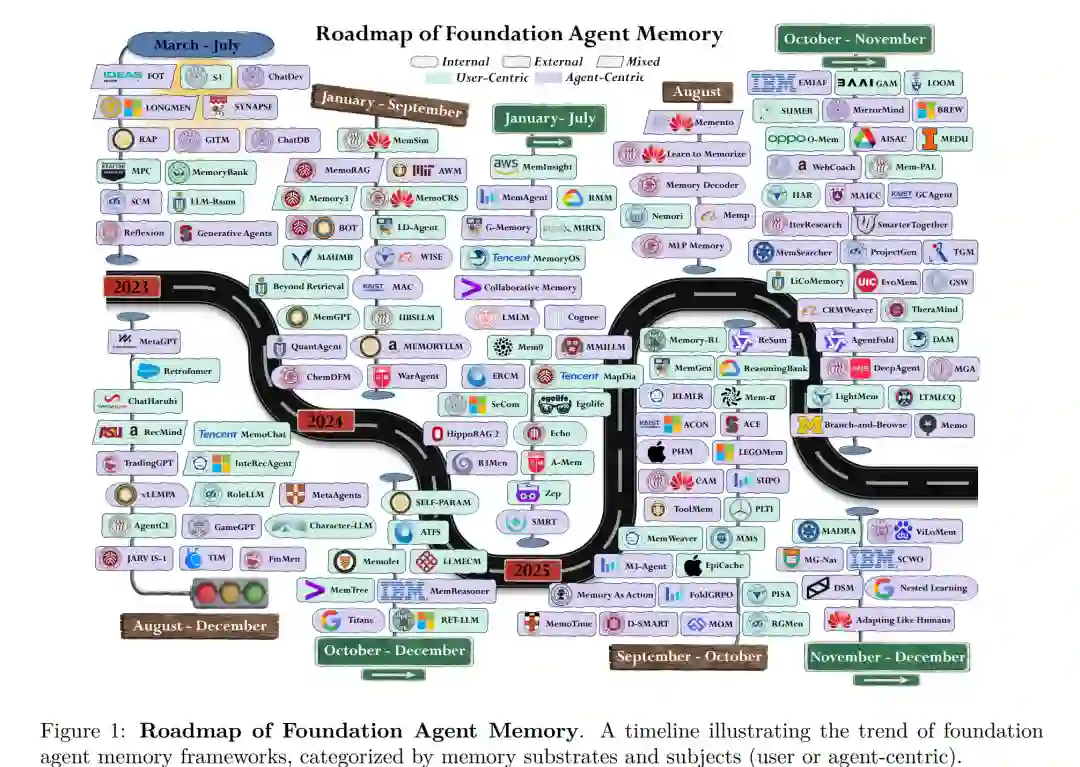
人工智能的格局正经历一场根本性的范式转移:从优先考虑基础模型架构和简化基准测试(Benchmark)表现,转向强调问题定义与严谨的现实世界评估。这标志着 AI 发展“上半场”的结束。在上半场中,技术的进步主要由训练方法 (Liu et al., 2024a)、规模化效应 (He et al., 2016; Achiam et al., 2023; Gu et al., 2025) 以及模型架构 (Vaswani et al., 2017) 驱动,这些因素不断推高模型在标准化基准测试中的得分 (Wang et al., 2024n; Krizhevsky et al., 2012)。在这一阶段,领域演进遵循着扩大数据与模型规模的主流范式,形成了一套通用方案:即海量数据预训练 (Minaee et al., 2024) 配合后训练过程 (Ouyang et al., 2022),从而以惊人的准确率解决传统基准测试。在定义明确的训练流水线下,大语言模型(LLMs)和智能体(Agents)在 MMLU (Hendrycks et al., 2021b) 或 MATH (Hendrycks et al., 2021c) 等基准测试中可达到超过 90% 的准确率。因此,LLMs 和智能体已迅速从传统机器学习模型那样的静态预测器,进化为能够在各种任务和环境中进行复杂推理 (Wu et al., 2025f)、规划 (Li et al., 2025i) 和工具调用 (Huang et al., 2025a; Zou et al., 2025b) 的通用智能体。 尽管在标准基准测试上表现出色,但报告的性能与许多现实任务及环境中的实际效用(Utility)之间仍存在显著差距 (Yu et al., 2024b)。大多数评估协议在很大程度上简化了实验假设,设计了静态且预定义的规则,且任务设置相对简短且孤立 (Cobbe et al., 2021; Chen et al., 2021; Budzianowski et al., 2018)。特别是近期大多数智能体评估基准都局限于较短的执行时间,缺乏多轮长期的交互 (Wang et al., 2024k; Lu et al., 2025a)。结果是,这些评估已无法反映基础智能体在现实中的能力,因为现实中的交互本质上是长程(Long-horizon)、长上下文且深度依赖用户并具有高度复杂性的。随着该领域向更真实的场景转型——如具身智能体 (Li et al., 2024b)、GUI 自动化 (Ye et al., 2025a)、深度研究 (Huang et al., 2025c)、个人医疗保健 (Zhan et al., 2024) 以及人机协作 (Feng et al., 2024; Zou et al., 2025c)——运行环境的复杂性呈爆炸式增长,使智能体暴露在异常庞大且动态的上下文之中。在这种设置下,静态、单次(One-shot)的能力已不足够。相反,智能体必须在跨交互过程中积累、保留并有选择性地重用信息。因此,记忆(Memory)成为了弥合理想化基准性能与现实世界落地及环境之间差距的关键且自然的解决方案 (Zhang et al., 2025o)。 随着 AI 发展进入“下半场”,重心从改进训练方案转向解决现实中的关键效用问题 (Bell et al., 2025; Yao et al., 2025)。如何设计基准来评估现实环境中的智能体已成为最重要的挑战之一 (Xu et al., 2025c),特别是当智能体致力于沿两个主要经验维度进行适应时:面向用户的个性化 (Cai et al., 2025; Zhang et al., 2025m; Wu et al., 2025e) 和面向任务的专业化 (Ling et al., 2025; Zhang et al., 2025i)。在这两个维度中,特定用户的长期历史交互上下文,或诸如编程 (Islam et al., 2024) 和网络搜索 (He et al., 2024a) 等垂直任务的上下文,其扩展范围远超仅靠提示词(Prompt)机制所能承载的容量。随着日常交互产生多会话数据或项目工作中积累的上下文呈指数级增长,依赖静态记忆机制已难以为继。因此,记忆架构正从静态、预定义且简单的机制 (Hao et al., 2023; Hu et al., 2023) 向自适应、自演化且灵活的单元演进 (Liu et al., 2025g;f),以智能地存储、加载、总结、遗忘和精炼信息,为下游任务保留具信息化价值的经验。 虽然基础智能体记忆研究的迅速增长已催生了数篇综述,但在现实智能体效用背景下,从系统设计角度分析智能体记忆仍存在重要空白。这类记忆设计已从简短、孤立的提示词转向长程交互,智能体必须在爆炸式增长的上下文窗口、多会话工作流以及持久的现实用户关系中运行。早期工作通常主要按任务应用或管理策略来组织记忆 (Zhang et al., 2025o; Du et al., 2025),或采用受神经科学启发的视角,通过功能类比和记忆生命周期将 AI 记忆投射到人类记忆上 (Wu et al., 2025g; Liang et al., 2025)。尽管这些方法提供了有用的概念基础,但当上下文超出基础模型的限制时,它们未能系统地刻画底层的记忆基质(Memory substrates),也未明确建模记忆在智能体系统中所服务的主体(Subject)。因此,它们难以区分智能体记忆的优化目标,并忽视了对于在现实应用中设计和部署自主智能体系统至关重要的互补维度间的联系。最近的研究开始拓宽这一概念图景。特别是 Hu et al. (2025d) 沿形式、功能和时间动态组织了智能体记忆。尽管该工作对记忆进行了宝贵的整合,但仍具片面性,主要关注记忆在以智能体为中心(Agent-centric)的任务中如何发挥作用,而非记忆应如何为用户进行设计、优化和部署。受此启发,本综述分析了数百篇关于基础智能体记忆的论文,从三个主要的互补视角出发,将记忆与日益复杂的环境中的系统级设计选择联系起来。 具体而言,我们引入了一个围绕三个核心设计维度组织的统一分类法(如图 2 所示):记忆基质、认知机制和记忆主体。我们按基质将现有的基础智能体记忆工作分为内部和外部;按认知机制分为功能类别,如情节记忆、感觉记忆、工作记忆、语义记忆和程序记忆;按主体分为以用户为中心和以智能体为中心。从系统视角出发,我们进一步分析了这些基础智能体记忆系统在不同代理拓扑结构(Agent topologies)下的运行方式,区分了单代理系统中的基础记忆操作与多代理设置中的记忆路由。此外,我们强调了学习策略(Learning policies)日益增长的作用,展示了智能体如何越来越多地接受训练以攻克记忆管理本身,从而从交互历史中学习并随时间自我演进。为了反映环境变化对基础智能体记忆设计的影响,我们讨论了跨上下文长度和环境复杂性的可扩展性问题,并回顾了用于衡量记忆性能和效用的评估方法与指标。最后,我们概述了基础智能体记忆面临的六个开放性挑战,以指导下一代基础智能体记忆的设计。