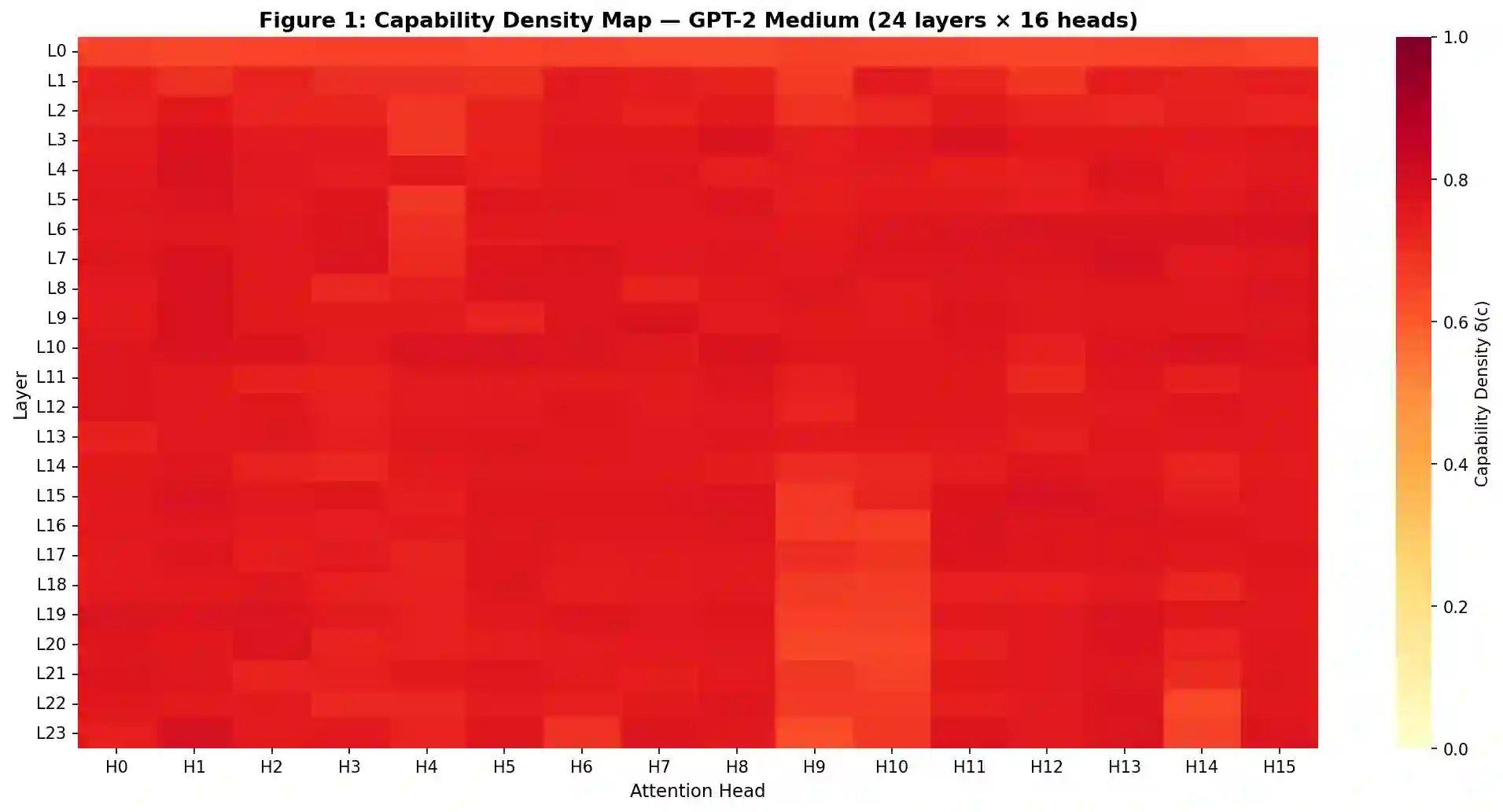
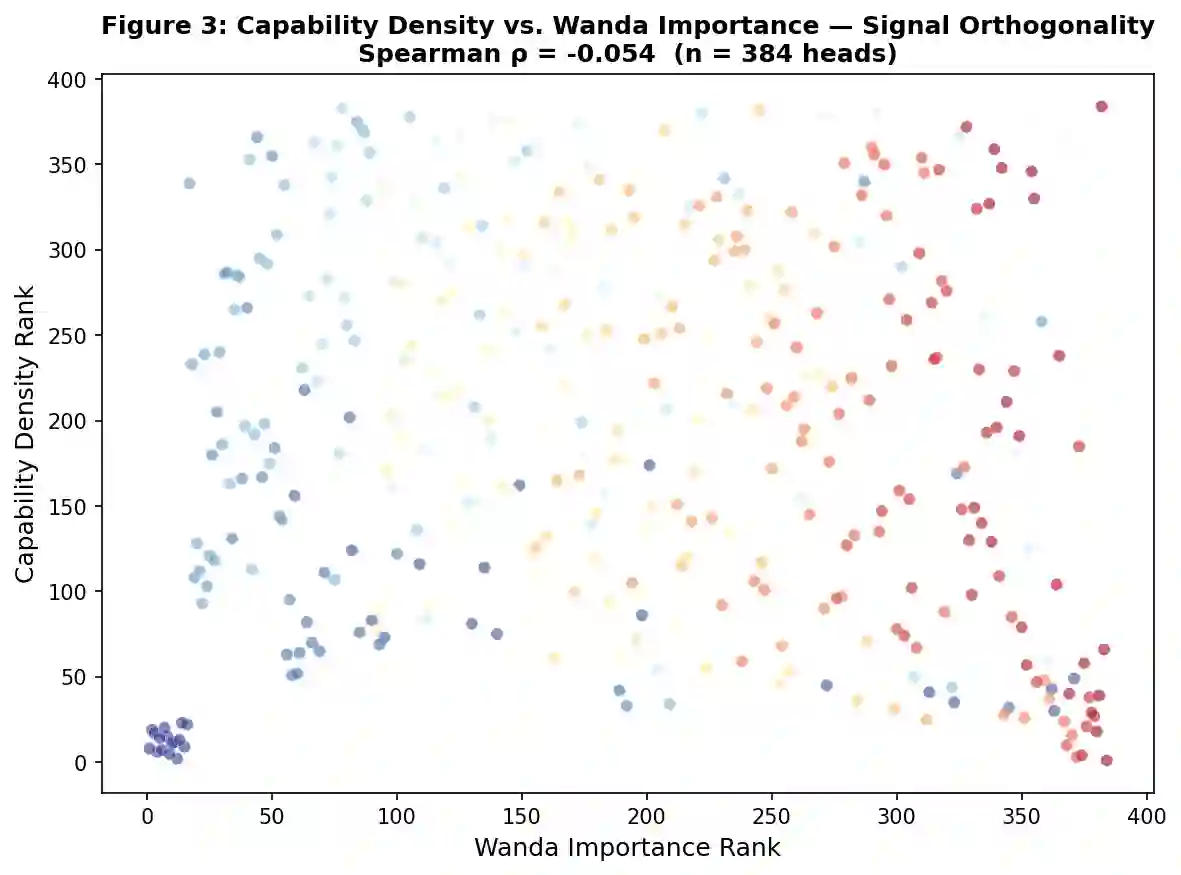
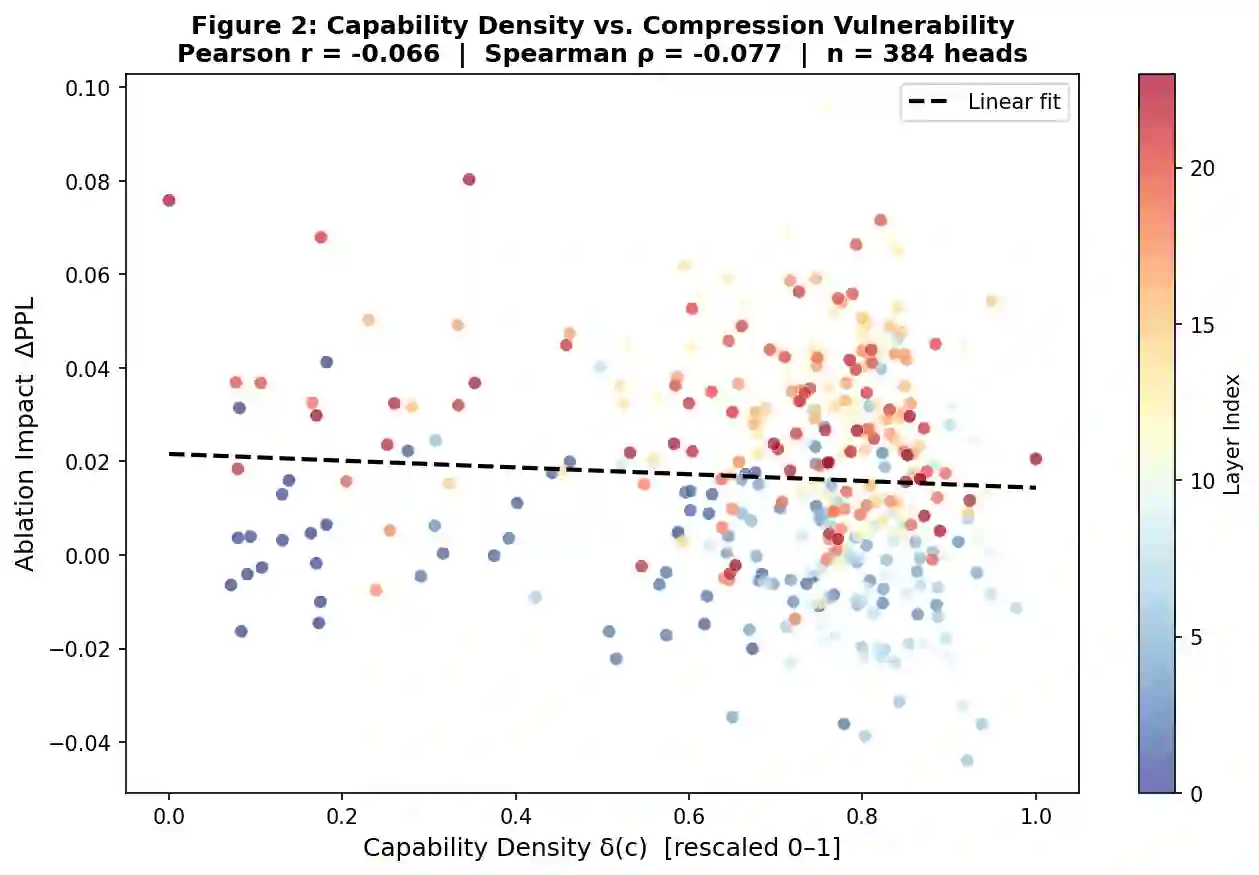
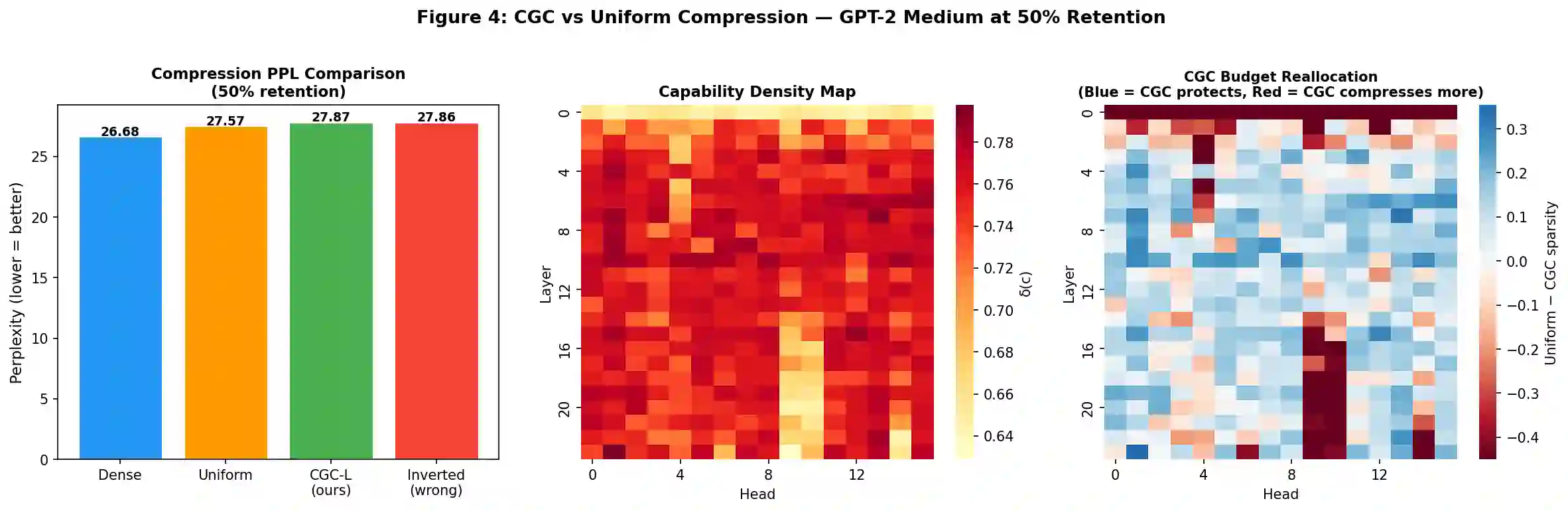
Large language model compression has made substantial progress through pruning, quantization, and low-rank decomposition, yet a fundamental limitation persists across all existing methods: compression budgets are allocated without any representation of what individual model components functionally encode. We term this the capability-blind compression problem and argue it is a root cause of two well-documented failures -- the insensitivity of perplexity-based evaluation to reasoning capability loss, and the abrupt phase transitions in model performance recently characterized by Ma et al. (2026). We propose Capability-Guided Compression (CGC), a framework that addresses this by using Sparse Autoencoder (SAE)-derived capability density maps to allocate differential compression budgets across transformer components. Capability density is a formally defined scalar measure combining the feature breadth, activation entropy, and cross-input consistency of a component's SAE feature activation distribution. We prove theoretically that components with higher capability density exhibit lower structural redundancy and reach their individual phase transition points at lower compression ratios, providing the first pre-compression mechanism for component-level phase transition prediction. Experiments on GPT-2 Medium confirm that capability density is statistically independent of Wanda importance scores (Spearman rho = -0.054, n = 384 heads), establishing it as a genuinely novel compression signal orthogonal to all existing importance metrics. We report a negative result on PPL-based compression comparison and provide a principled diagnosis identifying GPT-2 Medium as an insufficient test bed for the full CGC hypothesis. The theoretical framework, density formalism, and orthogonality finding constitute a foundation for capability-aware compression research.
翻译:大语言模型压缩通过剪枝、量化和低秩分解已取得实质性进展,但所有现有方法仍存在一个根本性局限:压缩预算的分配完全缺乏对模型各组件功能编码内容的表征。我们将此称为能力盲压缩问题,并论证这是两类已充分记录失效现象的根本原因——基于困惑度的评估对推理能力损失不敏感,以及Ma等人(2026)最近揭示的模型性能突变相变现象。我们提出能力导向压缩框架,通过采用稀疏自编码器衍生的能力密度图,在Transformer组件间实施差异化压缩预算分配。能力密度是形式化定义的标量度量,综合了组件SAE特征激活分布的特征广度、激活熵和跨输入一致性。我们理论证明:具有更高能力密度的组件展现出更低的结构冗余度,并在更低压缩比下达到其个体相变点,这为首个组件级相变预测的预压缩机制提供了理论基础。在GPT-2 Medium上的实验证实,能力密度与Wanda重要性分数具有统计独立性(Spearman ρ = -0.054,n = 384个注意力头),确立了其作为正交于所有现有重要性度量的全新压缩信号。我们报告了基于困惑度的压缩比较的负面结果,并通过原理性诊断指出GPT-2 Medium不足以作为完整CGC假说的测试平台。该理论框架、密度形式化体系及正交性发现共同构成了能力感知压缩研究的基础。