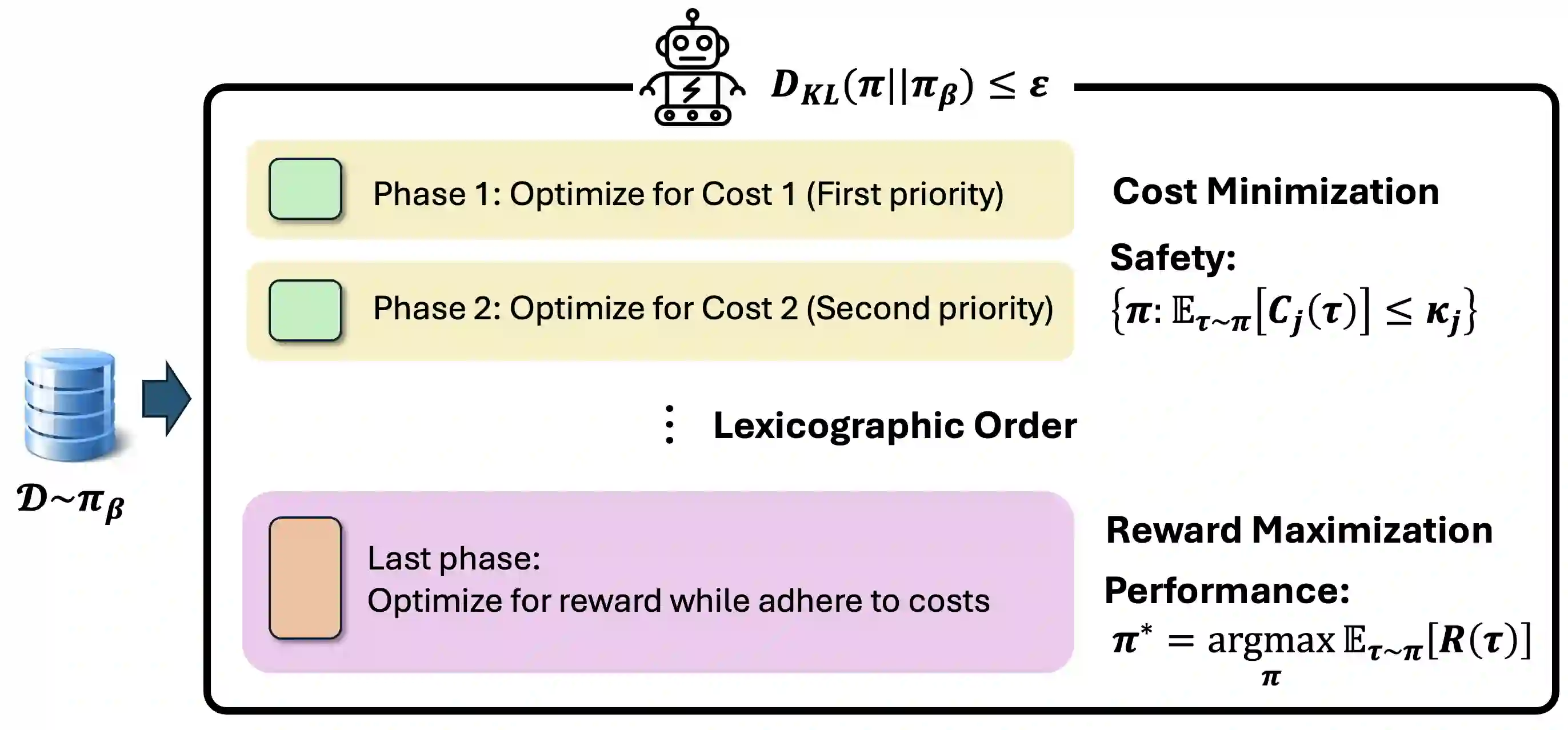
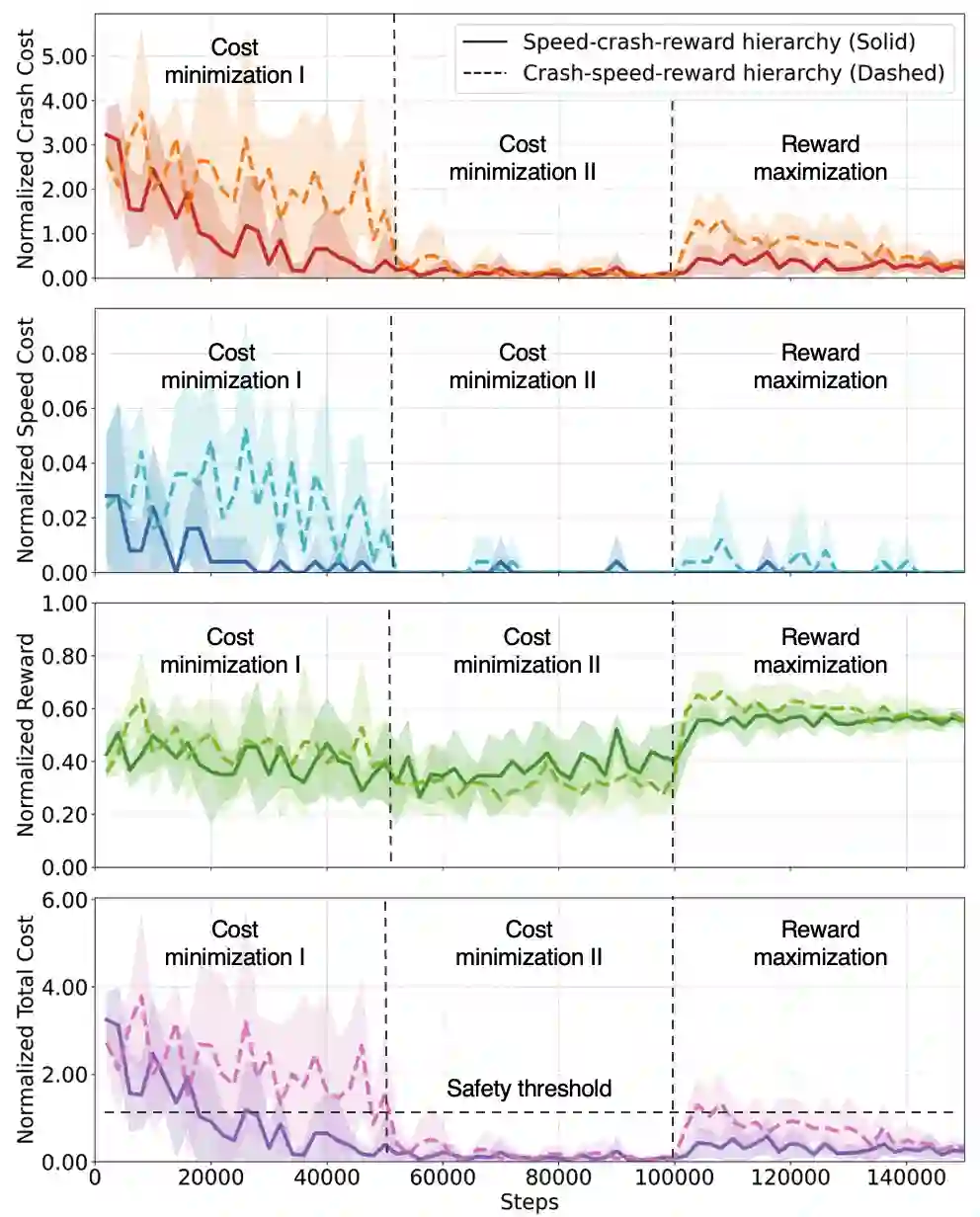
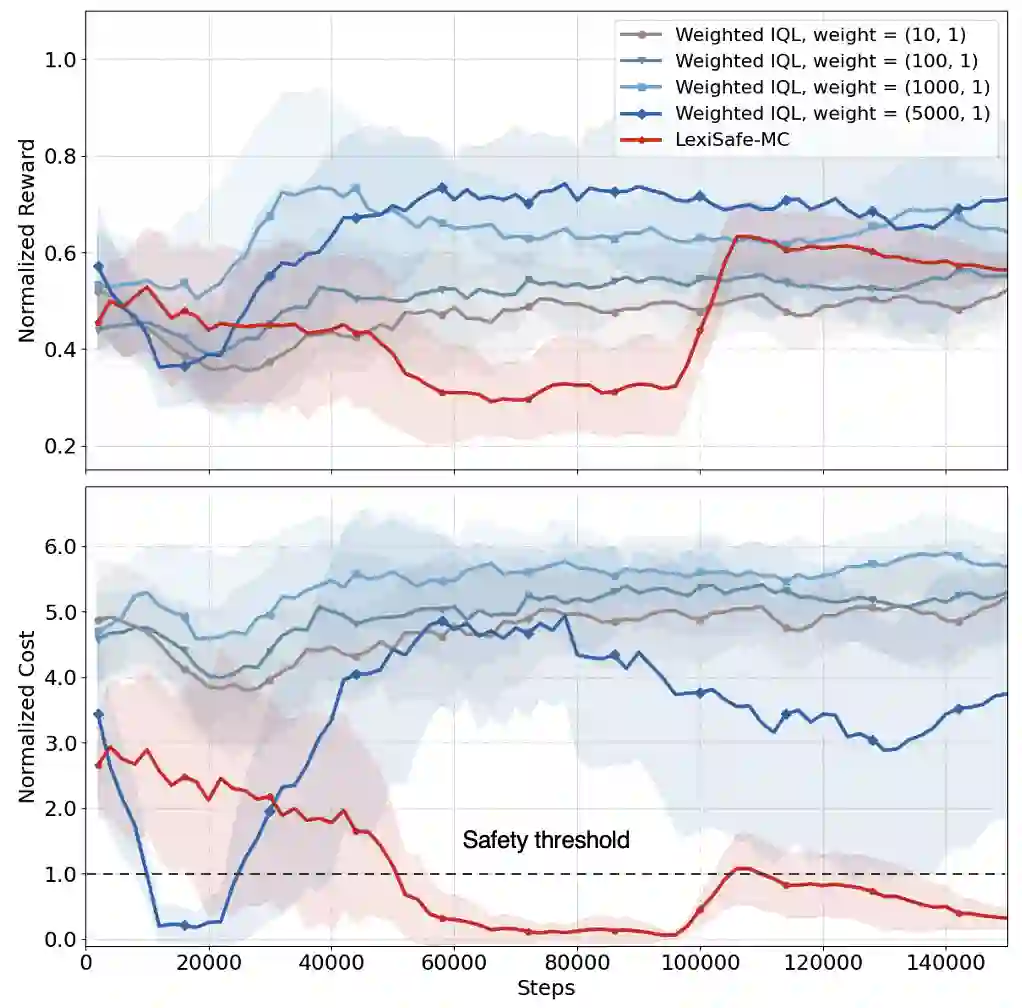
Offline safe reinforcement learning (RL) is increasingly important for cyber-physical systems (CPS), where safety violations during training are unacceptable and only pre-collected data are available. Existing offline safe RL methods typically balance reward-safety tradeoffs through constraint relaxation or joint optimization, but they often lack structural mechanisms to prevent safety drift. We propose LexiSafe, a lexicographic offline RL framework designed to preserve safety-aligned behavior. We first develop LexiSafe-SC, a single-cost formulation for standard offline safe RL, and derive safety-violation and performance-suboptimality bounds that together yield sample-complexity guarantees. We then extend the framework to hierarchical safety requirements with LexiSafe-MC, which supports multiple safety costs and admits its own sample-complexity analysis. Empirically, LexiSafe demonstrates reduced safety violations and improved task performance compared to constrained offline baselines. By unifying lexicographic prioritization with structural bias, LexiSafe offers a practical and theoretically grounded approach for safety-critical CPS decision-making.
翻译:离线安全强化学习(RL)对于信息物理系统(CPS)日益重要,因为在训练期间发生安全违规是不可接受的,且仅有预先收集的数据可用。现有的离线安全RL方法通常通过约束松弛或联合优化来权衡奖励与安全,但它们往往缺乏防止安全漂移的结构性机制。我们提出了LexiSafe,一个旨在保持安全对齐行为的词典序离线RL框架。我们首先针对标准离线安全RL开发了单成本公式LexiSafe-SC,并推导了安全违规和性能次优性界限,二者共同提供了样本复杂度保证。随后,我们将框架扩展至具有层次化安全需求的LexiSafe-MC,它支持多重安全成本并允许进行自身的样本复杂度分析。实验表明,与受限离线基线方法相比,LexiSafe展现出更少的安全违规和更好的任务性能。通过将词典序优先级与结构性偏差相统一,LexiSafe为安全关键型CPS决策提供了一种实用且理论依据充分的方法。