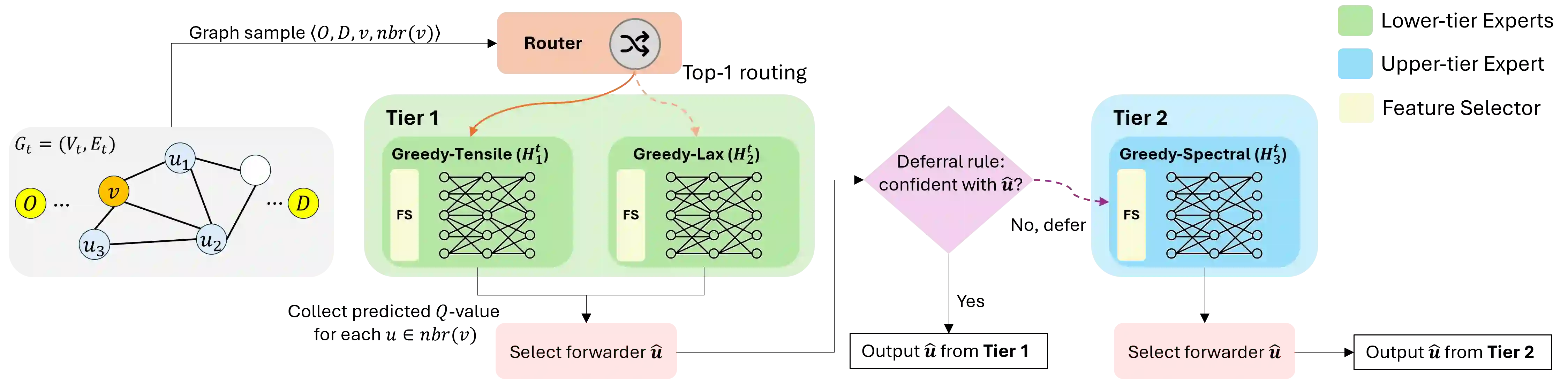
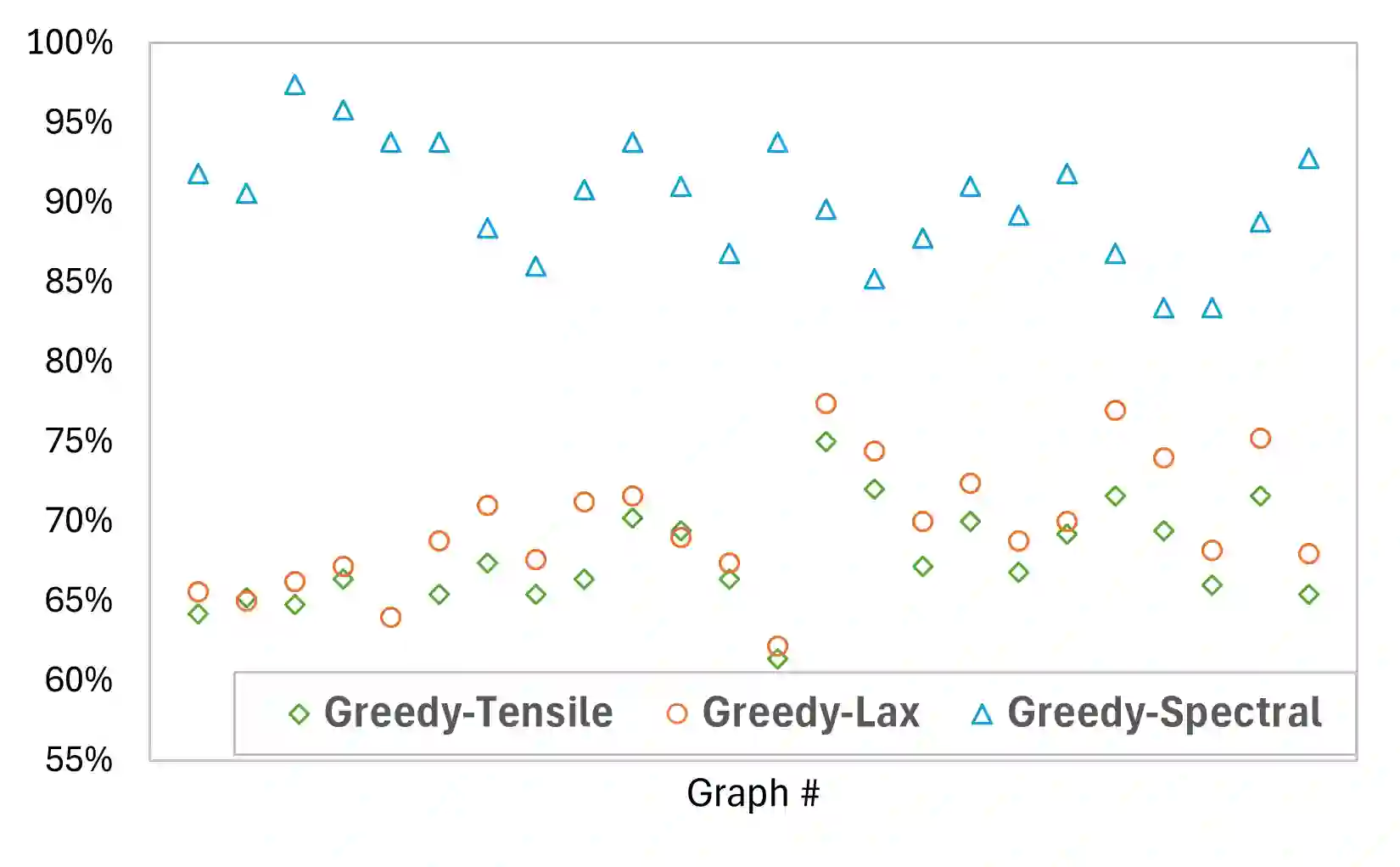
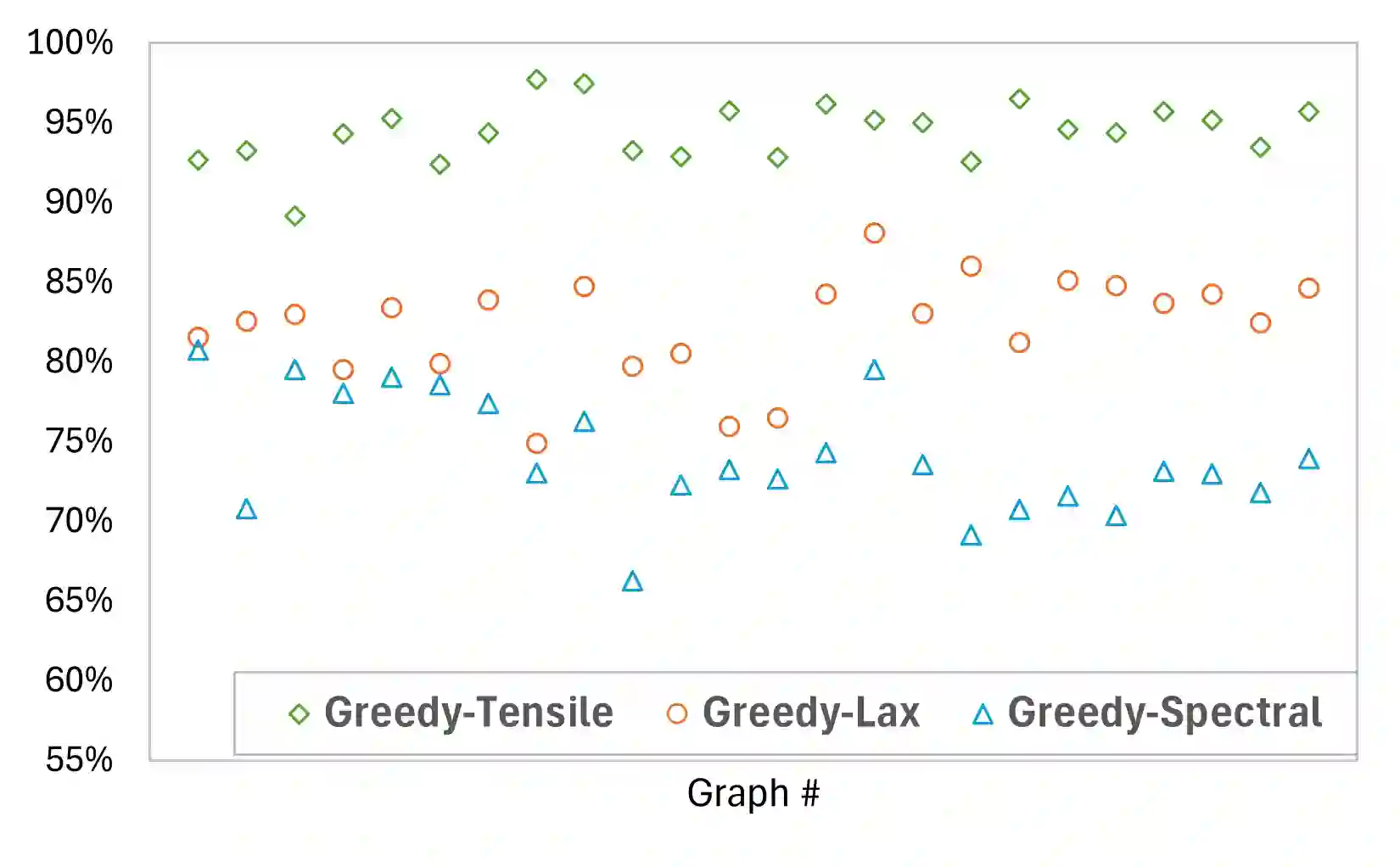
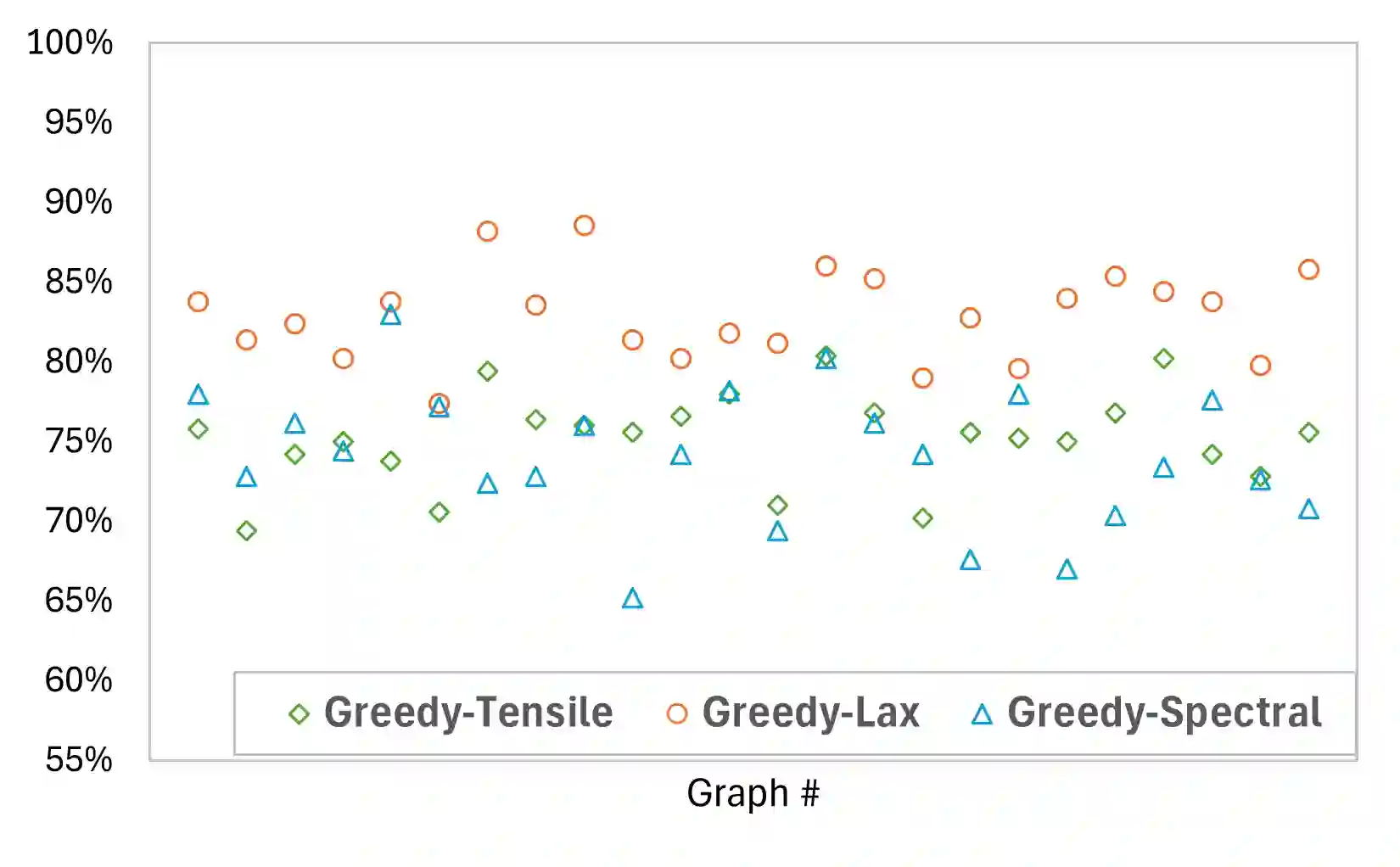
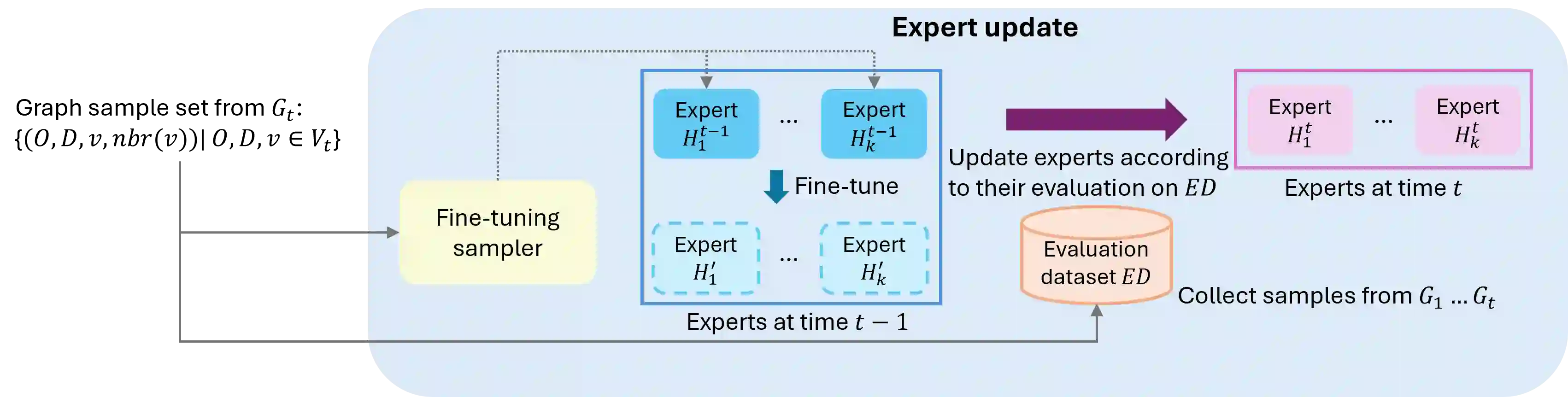
While deep learning models that leverage local features have demonstrated significant potential for near-optimal routing in dense Euclidean graphs, they struggle to generalize well in sparse networks where topological irregularities require broader structural awareness. To address this limitation, we train a Cascaded Mixture of Experts (Ca-MoE) to solve the all-pairs near-shortest path (APNSP) routing problem. Our Ca-MoE is a modular two-tier architecture that supports the decision-making for forwarder selection with lower-tier experts relying on local features and upper-tier experts relying on global features. It performs adaptive inference wherein the upper-tier experts are triggered only when the lower-tier ones do not suffice to achieve adequate decision quality. Computational efficiency is thus achieved by escalating model capacity only when necessitated by topological complexity, and parameter redundancy is avoided. Furthermore, we incorporate an online meta-learning strategy that facilitates independent expert fine-tuning and utilizes a stability-focused update mechanism to prevent catastrophic forgetting as new graph environments are encountered. Experimental evaluations demonstrate that Ca-MoE routing improves accuracy by up to 29.1% in sparse networks compared to single-expert baselines and maintains performance within 1%-6% of the theoretical upper bound across diverse graph densities.
翻译:尽管利用局部特征的深度学习模型在稠密欧几里得图中已展现出实现近最优路由的巨大潜力,但在拓扑结构不规则、需要更广泛结构感知的稀疏网络中,其泛化能力往往不足。为应对这一局限,我们训练了一个级联专家混合模型来解决全节点对近最短路径路由问题。我们的级联专家混合模型采用模块化的双层架构,支持转发节点选择的决策制定:下层专家依赖局部特征,而上层专家依赖全局特征。该模型执行自适应推理,仅当下层专家不足以达成足够决策质量时,才会触发上层专家。由此,模型能力仅在拓扑复杂性需要时才被提升,从而实现了计算效率,并避免了参数冗余。此外,我们引入了一种在线元学习策略,该策略便于专家独立微调,并采用一种侧重于稳定性的更新机制,以防止在遇到新图环境时发生灾难性遗忘。实验评估表明,与单专家基线模型相比,级联专家混合路由在稀疏网络中的准确率最高可提升29.1%,并且在不同的图密度下,其性能均能维持在理论上限的1%-6%以内。