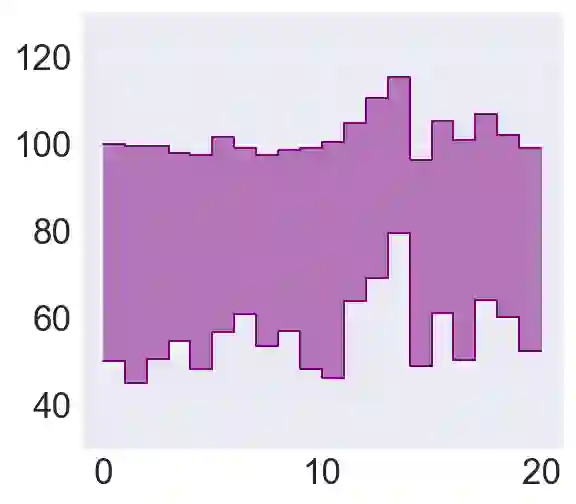
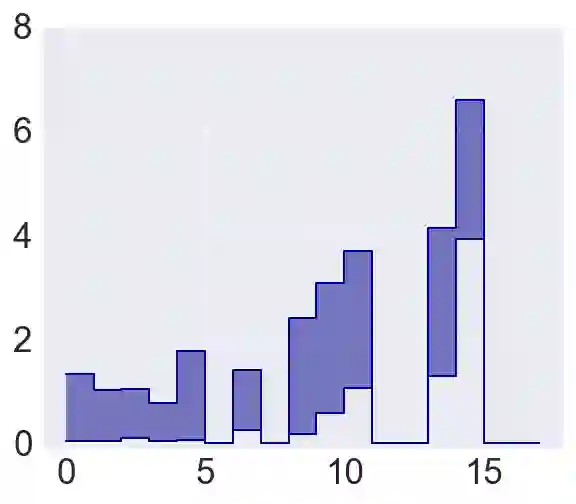
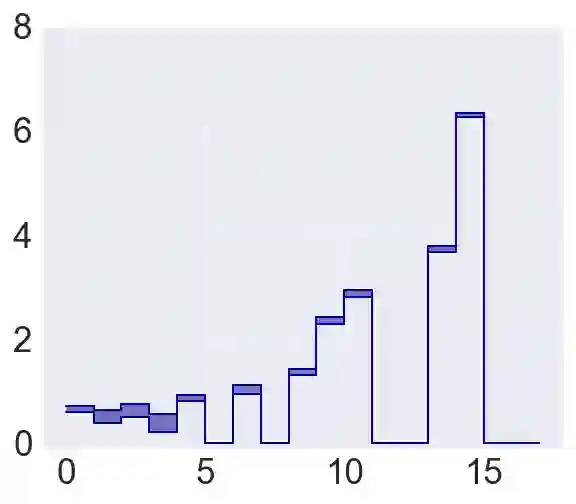
Policy evaluation is an important instrument for the comparison of different algorithms in Reinforcement Learning (RL). Yet even a precise knowledge of the value function $V^{\pi}$ corresponding to a policy $\pi$ does not provide reliable information on how far is the policy $\pi$ from the optimal one. We present a novel model-free upper value iteration procedure $({\sf UVIP})$ that allows us to estimate the suboptimality gap $V^{\star}(x) - V^{\pi}(x)$ from above and to construct confidence intervals for $V^\star$. Our approach relies on upper bounds to the solution of the Bellman optimality equation via martingale approach. We provide theoretical guarantees for ${\sf UVIP}$ under general assumptions and illustrate its performance on a number of benchmark RL problems.
翻译:政策评估是比较加强学习中不同算法的重要工具。然而,即使精确地了解与政策相对应的值函数$V ⁇ pi}$(pi$),也无法提供可靠信息,说明政策离最佳政策有多远。我们提出了一个新型无模型的上值迭代程序$(sf UVIP}),使我们能够估算上述低于最佳差值$V ⁇ star}(x)-V ⁇ pi}(x)美元,并为美元建立信任间隔。我们的方法依赖于通过马丁格尔方法解决贝尔曼最佳方程式的上限。我们在一般假设下为美元提供理论担保,并展示其在若干基准RL问题上的表现。