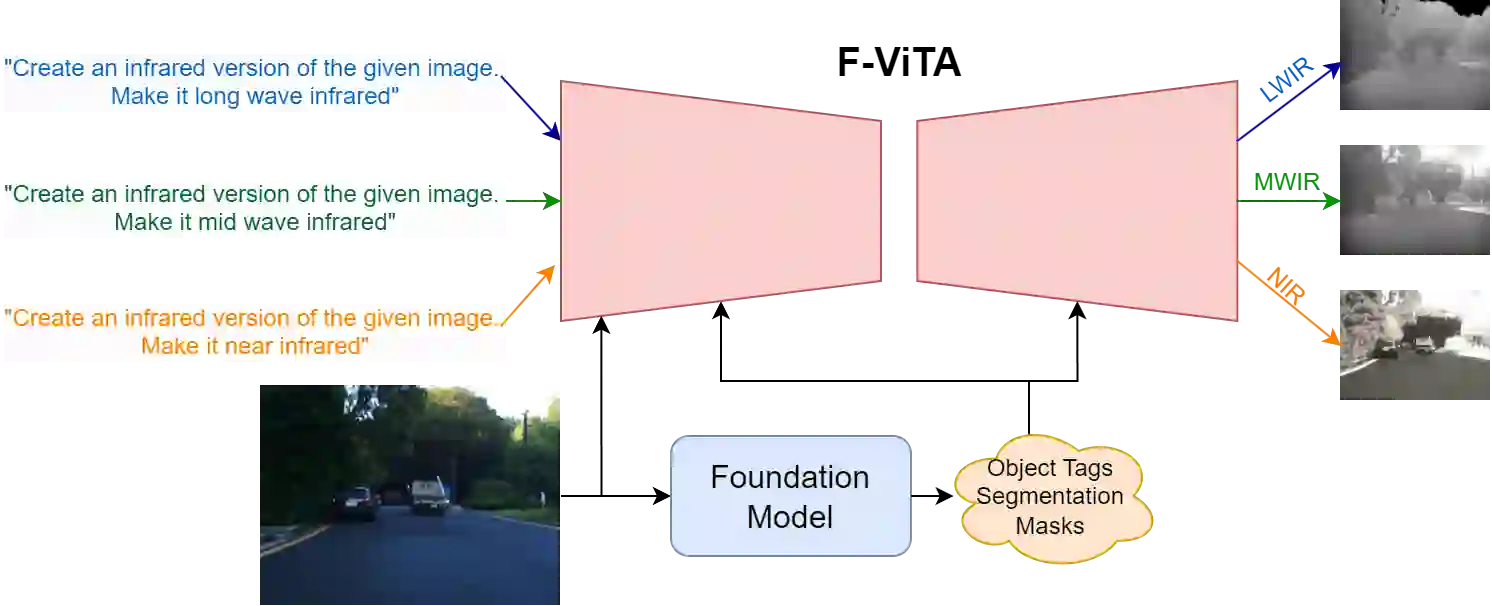
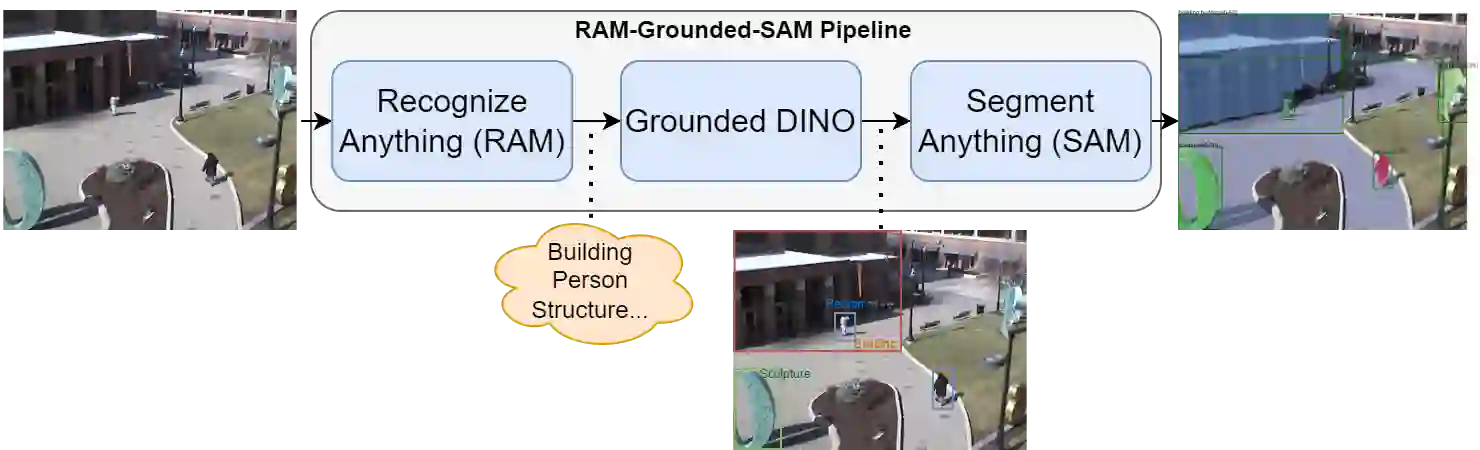
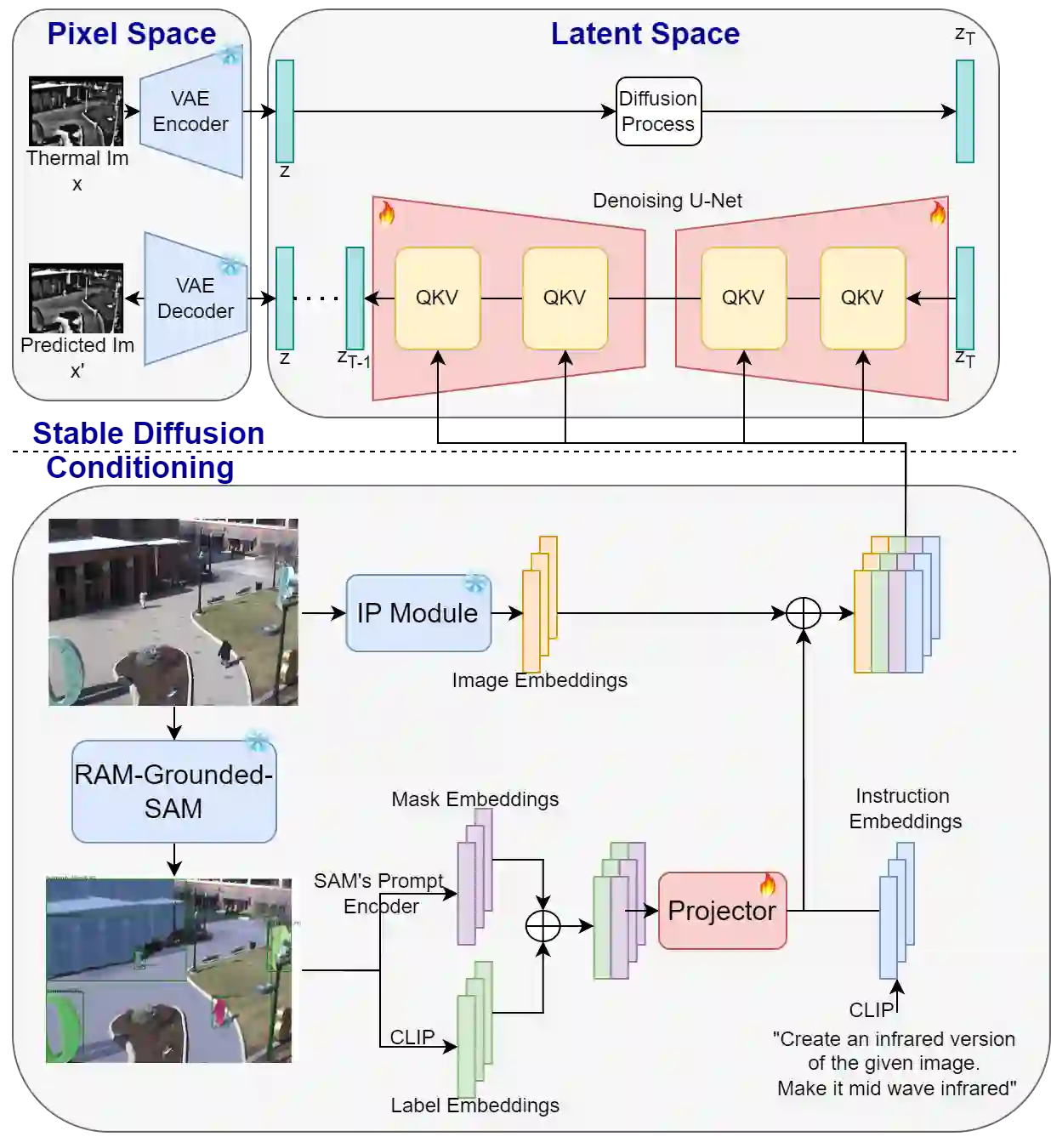
Thermal imaging is crucial for scene understanding, particularly in low-light and nighttime conditions. However, collecting large thermal datasets is costly and labor-intensive due to the specialized equipment required for infrared image capture. To address this challenge, researchers have explored visible-to-thermal image translation. Most existing methods rely on Generative Adversarial Networks (GANs) or Diffusion Models (DMs), treating the task as a style transfer problem. As a result, these approaches attempt to learn both the modality distribution shift and underlying physical principles from limited training data. In this paper, we propose F-ViTA, a novel approach that leverages the general world knowledge embedded in foundation models to guide the diffusion process for improved translation. Specifically, we condition an InstructPix2Pix Diffusion Model with zero-shot masks and labels from foundation models such as SAM and Grounded DINO. This allows the model to learn meaningful correlations between scene objects and their thermal signatures in infrared imagery. Extensive experiments on five public datasets demonstrate that F-ViTA outperforms state-of-the-art (SOTA) methods. Furthermore, our model generalizes well to out-of-distribution (OOD) scenarios and can generate Long-Wave Infrared (LWIR), Mid-Wave Infrared (MWIR), and Near-Infrared (NIR) translations from the same visible image. Code: https://github.com/JayParanjape/F-ViTA/tree/master.
翻译:热成像对于场景理解至关重要,尤其在低光照和夜间条件下。然而,由于红外图像采集需要专用设备,收集大规模热红外数据集的成本高昂且劳动密集。为应对这一挑战,研究者们探索了可见光至热红外图像的转换。现有方法大多依赖于生成对抗网络(GANs)或扩散模型(DMs),将任务视为风格迁移问题。因此,这些方法试图从有限的训练数据中同时学习模态分布偏移和潜在的物理原理。本文提出F-ViTA,一种新颖的方法,利用基础模型中嵌入的通用世界知识来引导扩散过程,以改进图像转换。具体而言,我们使用来自SAM和Grounded DINO等基础模型的零样本掩码和标签来条件化InstructPix2Pix扩散模型。这使得模型能够学习场景物体与其在红外图像中热特征之间的有意义关联。在五个公开数据集上的大量实验表明,F-ViTA的性能优于现有最先进(SOTA)方法。此外,我们的模型在分布外(OOD)场景中表现出良好的泛化能力,并能从同一可见光图像生成长波红外(LWIR)、中波红外(MWIR)和近红外(NIR)转换。代码:https://github.com/JayParanjape/F-ViTA/tree/master。