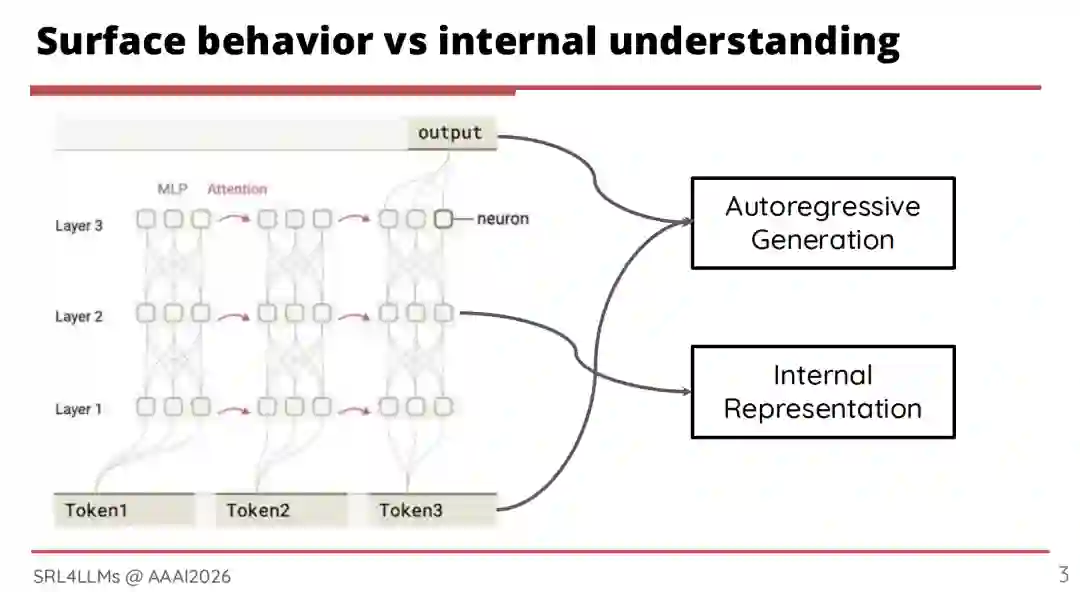
随着大语言模型(LLMs)从实验室研究走向实际应用,鉴于其演进速度之快及其内部机制的不可透明性(Opaque),理解并控制其行为已变得至关重要。本教程探讨了将规范化表征学习作为实现可控性、可解释性和迁移性的基础。参与者将学习如何构建可解释的模块化表征,以引导模型行为、提高推理效率,并通过表征重组(Recombination)将模型能力扩展至新任务。本教程植根于以人为本的度量体系和严谨的数据设计,为构建更具鲁棒性、透明且可信的 LLM 辅助系统提供了演进路线图。