

论文题目:CoT-Evo: Evolutionary Distillation of Chain-of-Thought for Scientific Reasoning
本文作者:冯科华(浙江大学)、丁科炎(浙江大学)、朱智慧(浙江大学)、梁磊(蚂蚁集团)、张强(浙江大学)、陈华钧(浙江大学)
发表会议:ICLR 2026
论文链接:https://arxiv.org/pdf/2510.13166
代码链接:https://github.com/Irving-Feng/CoT-Evo
欢迎转载,转载请注明出处****

一、引言
随着 DeepSeek-R1 和 OpenAI-o1 等推理型大语言模型(LLMs)的最新进展,利用长且结构化的思维链(CoT)已显著提升了复杂推理任务的表现。从先进的教师模型中蒸馏 CoT 已在通用领域证明有效。然而,当应用于科学领域时,由于任务的高复杂性和专业知识要求,即使是最强的 LLM 也经常产生错误或肤浅的推理路径。直接从这些有缺陷的输出中进行蒸馏会导致训练数据质量低下,限制了学生模型的性能。针对这一问题,本文提出了 CoT-Evo,一种进化的 CoT 蒸馏框架。
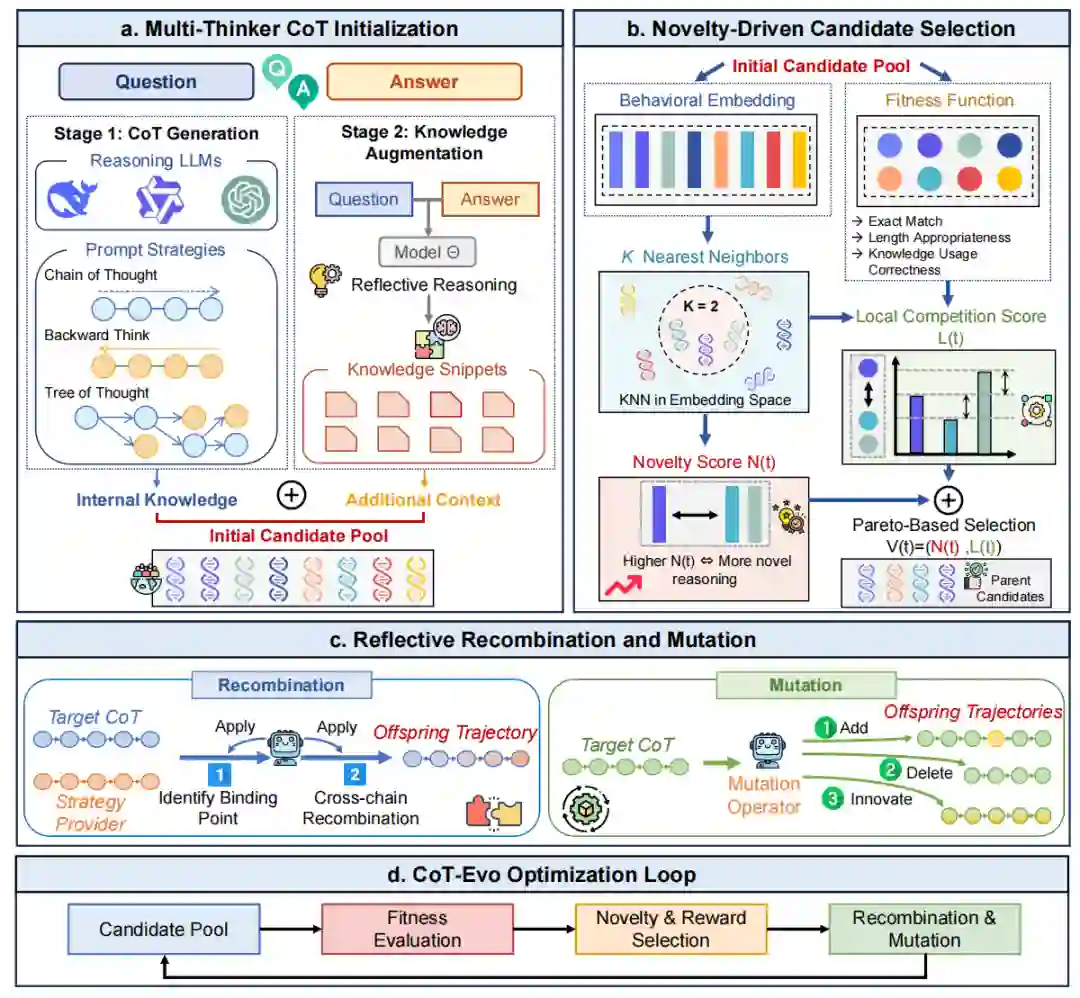
该框架不是从教师模型中选择单一的最佳推理路径,而是通过链内聚合(Intra-chain aggregation),动态整合来自多个 CoT 的思维,合成单一的高质量思维链。它首先利用多个 LLM “思考者”构建多样化的推理轨迹池,利用检索到的领域知识对其进行增强,并使用新颖性驱动的选择(Novelty-driven selection)、反思性重组(Reflective recombination)和变异(Mutation)迭代地细化轨迹。这一过程由评估答案正确性、连贯性和知识利用有效性的适应度函数指导。我们在科学推理基准上的实验表明,CoT-Evo 生成的数据能显著提升学生模型的性能,甚至在某些任务上超越了教师模型本身。 二、方法
CoT-Evo 借鉴遗传算法的原理,旨在为下游训练生成高保真、紧凑的 CoT。其核心包含四个模块:多思维者 CoT 初始化、适应度函数定义、新颖性驱动的候选筛选、以及反思性 CoT 重组与变异。
2.1. 多思维者 CoT 初始化 (Multi-Thinker CoT Initialization)
为了构建多样化且有潜力的初始候选池 ,我们采用两阶段方法:
- CoT 生成:集合多个 LLM “思考者”(如 DeepSeek-R1, Qwen3 等)以及不同的提示策略(如 CoT, ToT, Backward Reasoning)生成初始轨迹。
- 知识增强:考虑到科学领域的高专业性,模型内部知识可能不足。我们通过提示高级模型进行反思性推理,识别解决问题所需的知识并提取为片段 ,然后将这些知识作为附加上下文提供给思考者,生成知识增强的 CoT。
2.2 适应度函数 (Fitness Function)
我们使用复合适应度评分 来评估每个候选轨迹 :
- 精确匹配 ():二值分数,检查最终答案是否与标准答案完全匹配。
- 长度适宜性 ():惩罚过短(可能遗漏关键知识)或过长(可能冗余)的推理,鼓励简洁且解释充分的输出。
- 知识使用正确性 ():利用 LLM-as-a-Judge 评估核心思维中应用知识的准确性(1-5分)。 最终适应度函数定义为:
2.3 新颖性驱动的候选筛选 (Novelty-Driven Candidate Selection)
为了防止过早收敛并鼓励探索多样化的推理模式,CoT-Evo采用了一种受局部竞争新颖性搜索(NSLC)启发的选择机制。这种方法在奖励局部质量改进的同时,共同促进了独特的推理模式。
-
行为嵌入:将轨迹 映射到行为空间向量 。
-
新颖性评分 ():计算轨迹与其 个最近邻的平均距离,以此量化推理风格的独特性:
-
局部竞争评分 ():评估轨迹相对于其邻居的适应度提升:
最后,通过基于帕累托(Pareto)的筛选机制,选择在多样性和局部表现上均优异的父代候选者。
2.4 反思性 CoT 重组与变异 (Reflective Recombination and Mutation)
这些操作符通过策略性集成和改进,能够生成更优的子代链:
-
CoT 重组 (Recombination):当目标 CoT 答案错误时触发。该模块识别“策略提供者” 中的有效逻辑片段,通过寻找结合点(Binding Point),将 中的独特步骤和知识“嫁接”到 的合理前缀上,生成新的混合轨迹。
-
CoT 变异 (Mutation):旨在修正 的策略或逻辑。包括三种模式:
-
添加 (Additive):丰富逻辑细节和领域知识。
-
删除 (Deletive):修剪冗余和无效探索。
-
创新 (Innovative):利用正确答案诊断 的逻辑谬误,并生成试图避免该错误的新轨迹。
三、实验分析
3.1 实验设置
数据集:我们选择了两个具有代表性的科学推理数据集:
- ChemCoTDataset:涵盖分子理解、编辑、反应预测和优化,强调逐步的化学操作推理。
- BioProBench:评估生物实验方案的推理能力,包括方案问答、步骤排序和错误纠正。
模型:
- 教师模型 (LLM Thinkers):DeepSeek-R1, Qwen3-235B/32B, Llama4-Scout 等。
- 学生模型:Qwen3-8B, Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct。
基线方法: 我们将 CoT-Evo 与 Single Teacher (ST)、Multi Teacher (MT)、Best-of-K (BoK)、Retro-Search 和 TwT 等现有蒸馏方法进行了比较。
3.2. 主要实验结论
**3.2.1 总体性能对比
**![]()
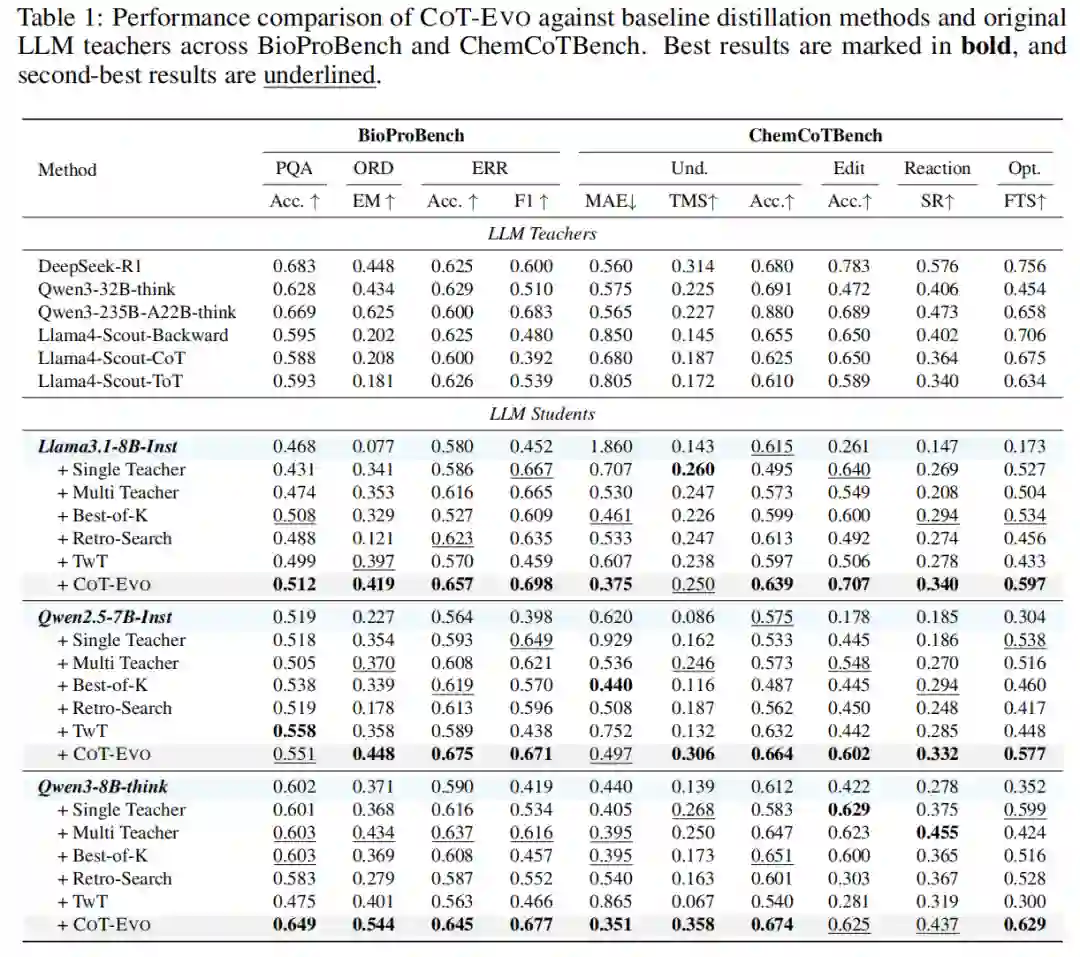
表 1 展示了 CoT-Evo 与各基线方法在 BioProBench 和 ChemCoTBench 上的性能对比。 结果显示,CoT-Evo 在所有任务上均显著优于单教师 (ST) 和多教师 (MT) 基线。例如,在 ChemCoTBench 上,相对于 ST 和 MT,CoT-Evo 分别带来了 27.0% 和 19.3% 的相对提升。值得注意的是,CoT-Evo 蒸馏出的学生模型在某些任务上甚至能够媲美甚至超越强大的教师模型本身。这表明 evolutionary 过程不仅仅是筛选,更是创造了更高质量的训练数据。此外,与 Best-of-K 相比的优势证实了性能提升源于 CoT 质量的进化,而非单纯的数据规模增加。
**3.2.2 数据利用率与质量分析
**![]()
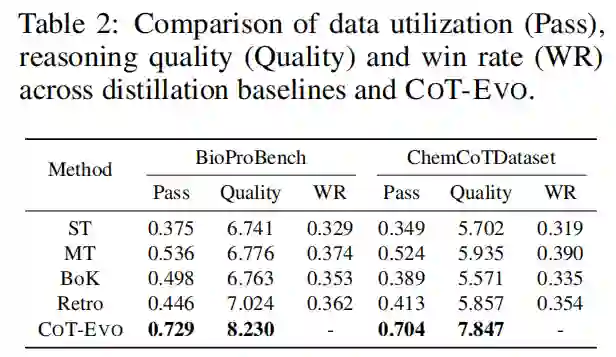
我们进一步分析了蒸馏数据的质量。如表 2 所示,CoT-Evo 保持了超过 70% 的数据可用率(Pass Rate),远高于基线。 在使用 GPT-5 作为裁判的质量评分(Quality)和成对胜率(Win Rate)评估中,CoT-Evo 生成的 CoT 在知识丰富度、逻辑紧凑性方面均表现更佳。基线模型在与 CoT-Evo 的对决中胜率均低于 40%,证明了 CoT-Evo 生成的是“更好的数据“。
**3.2.3 消融实验与可扩展性
**![]()
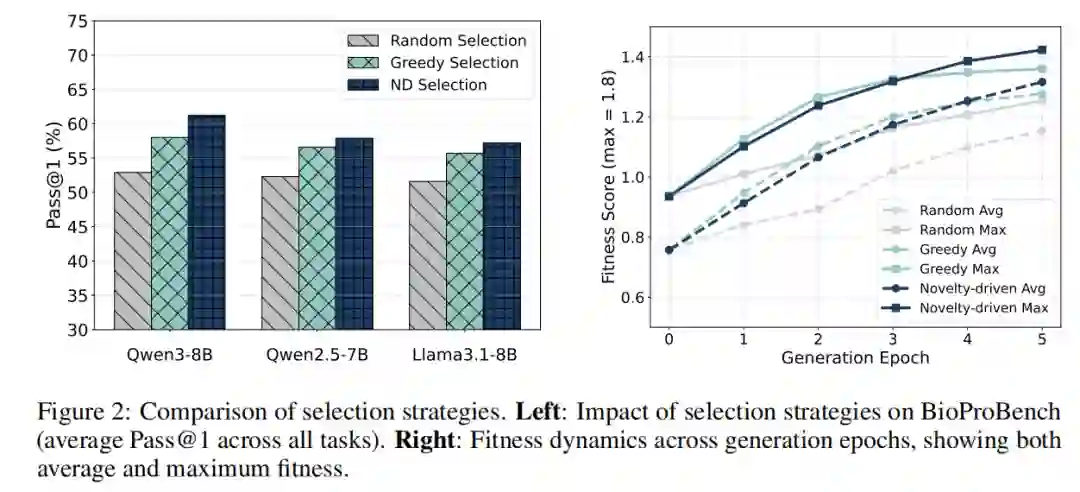
我们对新颖性驱动选择(NDS)策略进行了消融研究(图 2)。结果表明,相比于贪婪选择(Greedy)和随机选择(Random),NDS 能带来更快且更稳定的性能增益,避免了陷入局部最优。
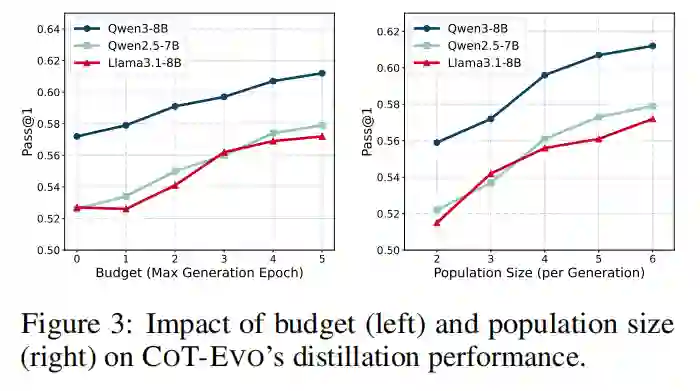
在可扩展性方面(图 3),随着迭代预算(Budget)和种群大小(Population Size)的增加,CoT-Evo 的性能持续提升,并在适度的计算预算下即可达到接近饱和的收益,证明了算法的高效性。
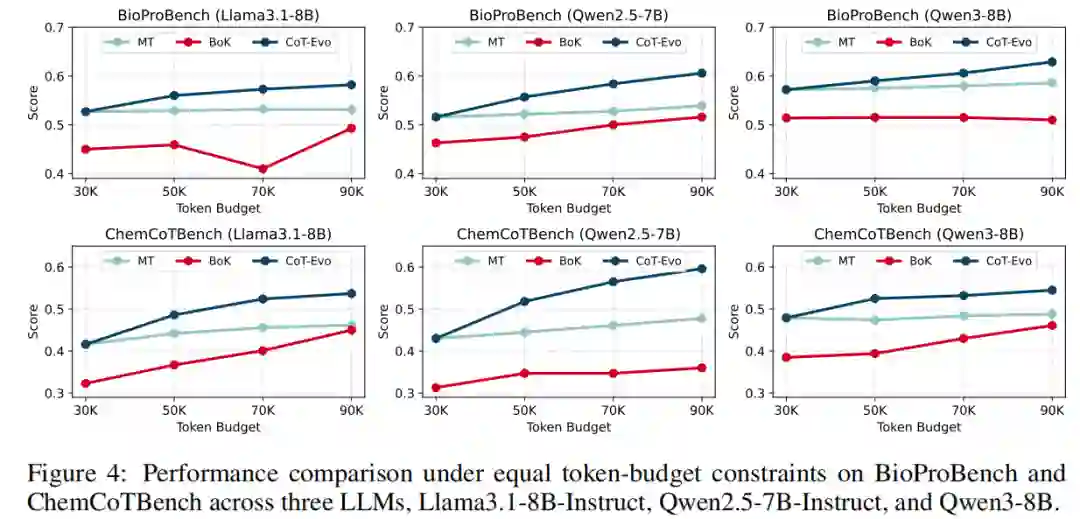
即使在严格控制总 Token 预算的情况下(图 4),CoT-Evo 依然一致地优于 MT 和 BoK 方法。 四、总结
本文介绍了 CoT-Evo,这是一个用于科学推理思维链蒸馏的进化框架。与现有方法不同,CoT-Evo 实现了链内聚合,通过迭代的评估-选择-变异-更新循环,精细地整合了来自多个来源的推理步骤。这种设计产生的蒸馏 CoT 在准确性、严谨性和多样性上均有显著提升,同时保持了紧凑性,非常适合训练较小的科学模型。大量实验证明,CoT-Evo 持续优于现有的蒸馏方法。未来,我们将探索其在更广泛科学领域的泛化能力,并结合外部结构化知识图谱进一步增强知识增强阶段。